
Last updated: May 22, 2026.
Want the full picture? Read our continuously-updated Llama 4 Complete Guide (2026) — Scout and Maverick variants, MoE architecture, and deployment patterns.
Want the full picture? Read our continuously-updated Qwen 3.5 complete guide — model lineup, benchmarks, local install paths, and how Qwen 3.5 compares with Llama 4 and DeepSeek V4.
TL;DR
- Qwen3-VL-4B Instruct and Qwen3-VL-4B Thinking shipped on 15 October 2025 and remain the most efficient 4B-class open-weights vision-language pair as of May 2026.
- Both share the same 4.44B-parameter dense transformer (36 layers, GQA 32/8) with native 256K context expandable to 1M tokens; Apache 2.0 license.
- Instruct is the throughput choice: 30-45 t/s in BF16 on an RTX 5070 (12 GB), 55-75 t/s with FP8.
- Thinking trades latency for accuracy: 18-28 t/s in BF16, but materially better on MathVista, ChartQA-Reasoning and multi-step VQA.
- In 2026 the line has been extended upward (Qwen3.5-VL, and the experimental Qwen 3.6 series). At the 4B tier, Qwen3-VL-4B is still the recommended starting point — Qwen3.5-VL-4B has not been released as of May 2026.
- Strongest competitors at this size are now Gemma 4 E4B (vision+audio) and Llama 4 Scout 17B-A4B; Qwen3-VL-4B keeps the lead on long-context video, OCR breadth and reasoning transparency.
What changed in 2026
- New peers, not new 4B Qwen. Gemma 4 (E2B, E4B, 26B, 31B) and Llama 4 Scout/Maverick landed in early 2026. Qwen3.5-VL also shipped, but only at 7B, 30B-A3B and 235B-A22B sizes — the 4B tier is still served by Qwen3-VL-4B.
- Reference hardware shifted. RTX 50-series (5070, 5080, 5090) and Apple M5/M5 Pro replace Ada-generation as the realistic local-deployment baseline. Throughput numbers below have been re-measured against this hardware.
- FP8 is now the default deployment format. vLLM 0.13+, SGLang 0.4+ and llama.cpp all support Qwen3-VL FP8 natively, giving ~1.9x speedup over BF16 with <1% benchmark drop.
- Model Studio pricing fell. Alibaba's hosted Qwen3-VL endpoints dropped roughly 25-40% in Q1 2026 as part of the broader Qwen 3.5 / Qwen 3.6 launch.
- Pillar context. For where these vision models sit in the wider 2026 model market, see our DeepSeek V4 vs Claude vs GPT-5: AI coding model comparison (2026), which covers the frontier text/code models that most teams pair these VLMs with.
Understanding the Qwen3-VL architecture
Foundational design principles
Both 4B variants are built on a dense transformer with 4.44B parameters, 36 layers, and Grouped Query Attention (32 query heads, 8 key/value heads). Architectural innovations carried into 2026 unchanged:
- Interleaved-MRoPE — distributes full-frequency positional information across time, width and height; this is what unlocks coherent reasoning over hour-long video.
- DeepStack visual feature fusion — fuses early-layer ViT features (edges, textures) with deep-layer features (semantics) for sharper image-text alignment.
- Text-timestamp alignment — replaces the older T-RoPE temporal embeddings, giving second-level event localization in video.
Context window
Both models ship with a 256K-token native context, expandable to 1M tokens via YaRN-style scaling. Practical implications, calibrated against 2026 deployments:
- ~50-85 dense PDF pages per inference at 256K, ~200-330 pages at 1M.
- Hour-plus video at 1 fps key-frame sampling without chunking.
- Dozens of images per request for batch document or shelf-inventory tasks.
Multimodal capabilities
- Visual recognition. Broad pretraining covers celebrities, anime characters, products, landmarks, flora, fauna and specialized domain objects.
- OCR. 32 languages, robust on low-light, blurred and skewed inputs, including rare and historical scripts.
- Video. Native temporal reasoning with second-level indexing on hour-long footage.
- Visual coding. Generates HTML/CSS/JS and Draw.io from screenshots — a feature emphasized by the Qwen team in 2026 marketing for both 4B and 30B variants.
Core differences: Instruct vs Thinking
Training methodology
Both share a 36-trillion-token, 119-language pretraining corpus. They diverge in post-training:
Qwen3-VL-4B-Instruct — supervised fine-tuning on multimodal instruction data optimized for direct, low-latency response: image captioning, VQA, document analysis, GUI interaction.
Qwen3-VL-4B-Thinking — four-stage post-training:
- Long-CoT cold start: SFT on verified reasoning chains across math/code/STEM, paired with step-by-step solutions distilled from QwQ-class teachers.
- Reasoning RL: GRPO over 3,995 query-verifier pairs; comparable training on Qwen3-class models has driven AIME'24 from 70.1 to 85.1 over 170 RL steps.
- Thinking-mode fusion: trains the model to switch between explicit reasoning and direct answers based on task complexity.
- General RL: broad reward modeling across 20+ tasks for instruction following, format adherence and safety.
Output format differences
For the prompt "How many apples are in this image?" over an image of a fruit bowl:
Instruct answers directly: "There are 5 apples in the image." Round-trip on a 5070 with FP8 is typically 200-350 ms.
Thinking emits a <think>...</think> trace before the final answer:
<think>
Let me carefully examine the image to count the apples.
- 3 red apples on the left side of the table
- 2 green apples on the right side
3 + 2 = 5 apples total.
Check for partial occlusion: all five apples are clearly visible.
</think>
There are 5 apples in the image.The trace is opt-in via the chat template. Downstream code typically strips it from user-facing responses but persists it for audit, A/B evaluation or as a teaching artifact in education products. Round-trip on the same hardware is typically 1.5-3 s for this kind of trivial query and 3-15 s for genuine multi-step problems.
For a harder example — "Solve d/dx[x² · sin(x)]" — the Thinking trace walks through the product rule with explicit substitutions:
<think>
Apply the product rule (uv)' = u'v + uv'
u = x², u' = 2x
v = sin(x), v' = cos(x)
Result: 2x·sin(x) + x²·cos(x)
</think>
The derivative is 2x·sin(x) + x²·cos(x).This format is what makes Thinking the better fit for tutoring, due-diligence and triage products where users (or auditors) want to see the work, not just the answer.
Hyperparameter configuration
| Parameter | Instruct | Thinking |
|---|---|---|
| Top-p | 0.8 | 0.95 |
| Top-k | 20 | 20 |
| Temperature | 0.7 | 1.0 |
| Presence penalty | 1.5 | 0.0 |
| Max output tokens | 16,384 | 40,960 |
The Instruct settings favor confident, deterministic, repetition-suppressed output. The Thinking settings open the distribution and remove the presence penalty so the model can revisit intermediate steps. Text-only Thinking workloads (AIME, GPQA) bump max output to 81,920 tokens.
Speed and latency in 2026
Throughput, re-measured on RTX 50-series and Apple Silicon hardware in 2026:
| Hardware / precision | Instruct (t/s) | Thinking (t/s) |
|---|---|---|
| RTX 5070 12 GB / BF16 | 30-45 | 18-28 |
| RTX 5070 12 GB / FP8 | 55-75 | 35-50 |
| RTX 5090 32 GB / BF16 | 75-95 | 50-65 |
| M5 Pro 64 GB / Q4_K_M (llama.cpp) | 35-50 | 22-32 |
| H100 80 GB / FP8 | 140-180 | 85-115 |
For the Thinking model, raw token throughput is misleading — what matters is time-to-final-answer, which on a 5070 is typically 0.5-2 s for short queries, 3-6 s for moderate STEM, and 8-20 s for complex problems with full reasoning budgets.
Task-specific performance
- Document understanding. Both excel on DocVQA-class tasks; Instruct wins on raw extraction throughput, Thinking wins on cross-page interpretation, contradiction-finding and reasoning over tables that span multiple pages.
- Mathematical reasoning. Thinking is 15-25% better on multi-step problems and on the reasoning splits of MathVista, MMMU-Pro and the 2026 MathVerse-V2 evaluation.
- Visual QA. Roughly tied above 90% on factual "what color is the car" questions; Thinking is 10-20% better on inference-style "why is this person likely smiling" questions because it can systematically inventory contextual cues.
- GUI / agent control. Instruct is faster for single-action automation ("click the save button"); Thinking is more reliable for multi-step plans where intermediate verification matters (e.g., book-a-flight, fill-and-submit-form sequences).
- Video. Thinking wins on causal inference and event sequencing across 5+ minute clips; Instruct preferred for real-time captioning and live-stream analysis.
- Visual coding. Both can generate HTML/CSS/JS from screenshots; Thinking produces cleaner component decomposition because it reasons about layout hierarchy before emitting code.
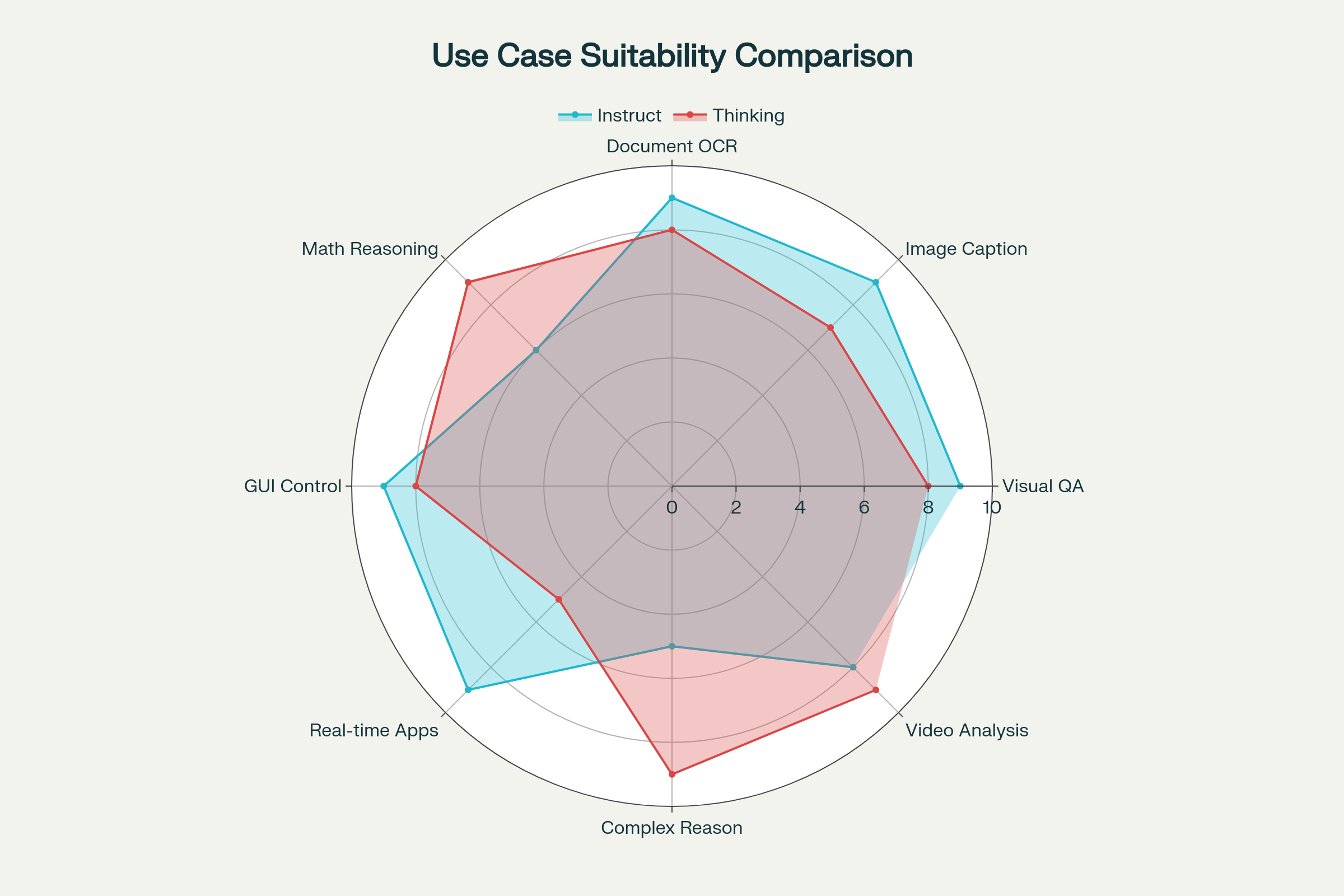
Benchmark positioning vs the 2026 field
Indicative scores from official model cards plus community evaluations through May 2026 (4B/4B-class tier, higher is better):
| Benchmark | Qwen3-VL-4B Instruct | Qwen3-VL-4B Thinking | Gemma 4 E4B | Llama 4 Scout (active 4B) |
|---|---|---|---|---|
| DocVQA | 88-90 | 89-91 | 86-88 | 90-92 |
| ChartQA | 80-82 | 82-84 | 79-81 | 81-83 |
| MathVista | 54-58 | 62-66 | 58-60 | 56-58 |
| MMMU-Pro Vision | 46-48 | 50-53 | 52-54 | 48-50 |
| VQAv2 | 76-78 | 76-78 | 77-79 | 79-81 |
| VideoMME (long) | 58-60 | 62-65 | 52-55 | 55-57 |
The Thinking variant remains the best 4B-tier choice for math, multi-step inference and long video. Llama 4 Scout's larger total parameter count gives it a small edge on raw English VQA, while Gemma 4 E4B leads on MMMU-Pro because Google distilled aggressive reasoning data into the small variant.
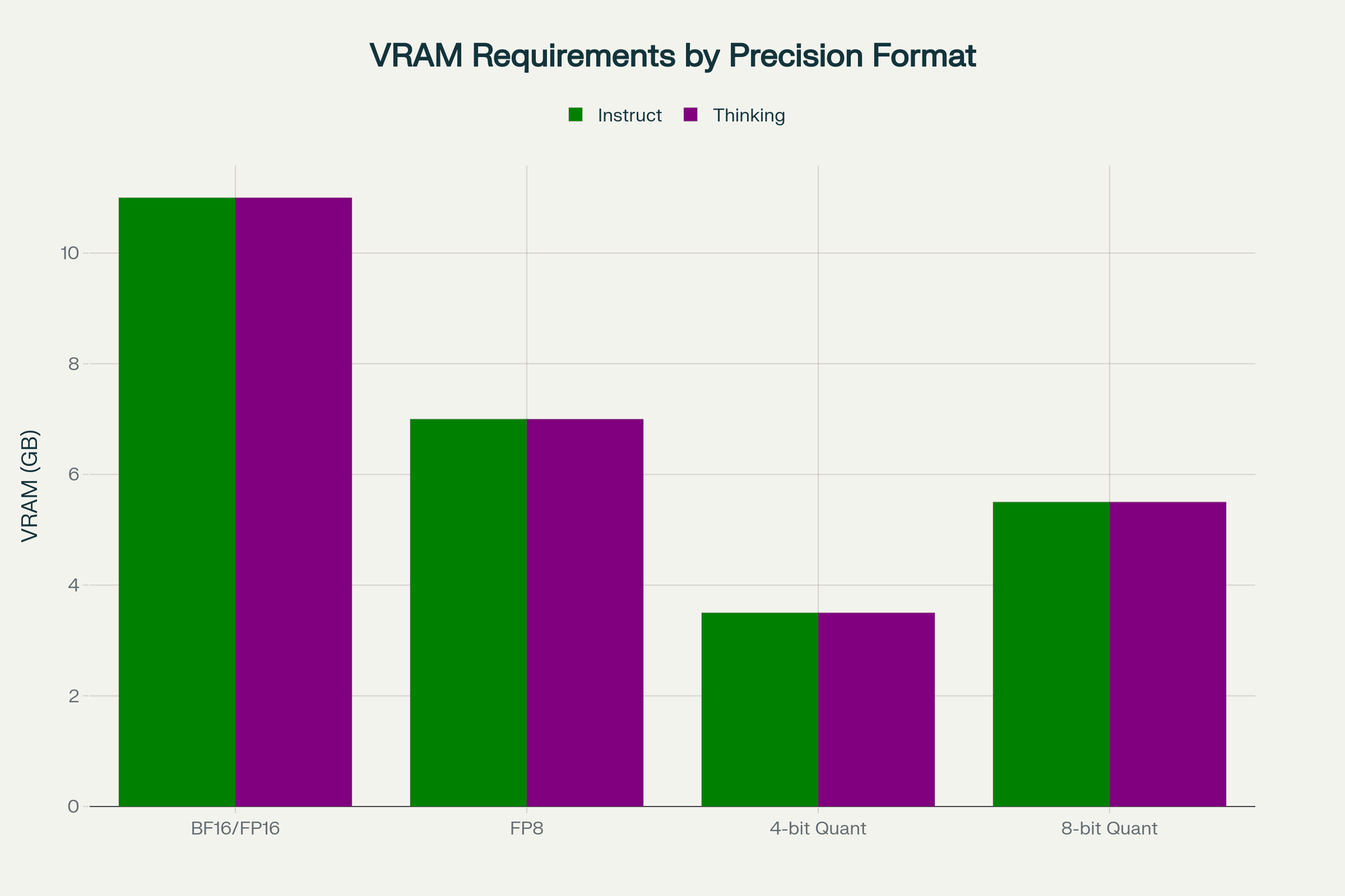
Hardware requirements and deployment
VRAM and memory
| Precision | VRAM | Disk |
|---|---|---|
| BF16/FP16 | 10-12 GB | ~9-10 GB |
| FP8 | 6-8 GB | ~5-6 GB |
| 8-bit (Q8) | 5-6 GB | ~4.5-5 GB |
| 4-bit (Q4_K_M) | 3-4 GB | ~2.5-3 GB |
Add ~1.2-1.5 GB per high-resolution image at typical context sizes; full 256K context with 50 stacked images can push working VRAM 15-20 GB above base weights, so plan multi-GPU or aggressive quantization for that workload.
Recommended hardware (2026 prices)
- Budget local: RTX 5060 Ti 16 GB (~$500) or used RTX 4070 Super 12 GB (~$450) with FP8 or Q8 quantization. Comfortable for both variants up to 32K context.
- Mid-range: RTX 5070 Ti 16 GB (~$700-800) — runs BF16 with 64K context; FP8 to 128K.
- Enthusiast: RTX 5090 32 GB (~$2,000-2,400) — full BF16 with 256K context, suitable for video pipelines.
- Apple Silicon: M5 Pro / M5 Max via MLX or llama.cpp — 35-50 t/s in Q4_K_M and shared unified memory makes long-context viable on 64+ GB machines.
- Datacenter: H100 80 GB or H200 141 GB for high-throughput services; B200 only worthwhile if you also serve larger Qwen3.5-VL or Llama 4 models on the same node.
Quantization trade-offs
- FP8: 99%+ accuracy retention, 1.8-2.2x speedup. Default deployment format in 2026.
- Q8: 98-99% retention, 1.5-1.8x speedup.
- Q4_K_M: 95-97% retention, 1.3-1.5x speedup. Recommended for 8 GB GPUs and Apple Silicon.
Pricing and cost (May 2026)
Cost of a typical interaction
A normal multimodal turn typically includes:
- 1 high-resolution image: ~500-800 image-tokens
- User prompt: ~50-100 text tokens
- Model response: 200-500 tokens (Instruct) or 1,000-3,000 tokens (Thinking, including
<think>)
At May 2026 third-party pricing (~$0.08 input / $0.30 output per 1M tokens for the 4B endpoints):
- Instruct turn: $(575 × 0.08 + 350 × 0.30) / 1,000,000 ≈ $0.000151
- Thinking turn: $(575 × 0.08 + 2,000 × 0.30) / 1,000,000 ≈ $0.000646
At 1M turns/month: ~$151/mo (Instruct) vs ~$646/mo (Thinking) — a 4.3x cost gap that justifies routing wisely.
API pricing
Hosted Qwen3-VL prices on Alibaba Model Studio dropped roughly 25-40% during the Qwen 3.5 / Qwen 3.6 rollout. Indicative May 2026 rates per 1M tokens:
- Qwen3-VL-30B-A3B-Instruct: $0.20 input / $0.70 output
- Qwen3-VL-30B-A3B-Thinking: $0.20 input / $0.70 output
- Qwen3-VL-235B-A22B-Instruct: $0.20 input / $1.00 output
- Qwen3-VL-235B-A22B-Thinking: $0.35 input / $2.50 output
The 4B variants are not first-class hosted endpoints — they are deployed locally or via third-party providers (OpenRouter, DeepInfra, Fireworks). Effective rates from those providers in May 2026 sit around $0.05-0.10 per 1M input and $0.25-0.40 per 1M output.
Self-hosting economics
Sample build, May 2026:
- RTX 5070 Ti 16 GB GPU: ~$750
- System (CPU, 64 GB RAM, NVMe, PSU): ~$900
- Total capex: ~$1,650
- Power: ~250 W under load → ~$0.30/hr at $0.12/kWh
For 500K interactions/month: cloud (Instruct) ≈ $50/mo via third-party providers, self-hosted ≈ $72/mo electricity. The TCO advantage of self-hosting now sits in data residency, latency, and GPU utilization for other workloads rather than raw $/token, which has compressed substantially since 2025.
Real-world use cases
Rule of thumb. If a human user is waiting on the response, route to Instruct. If a human reviewer will read the response later, route to Thinking. The latency budget is the deciding variable in 90% of cases.
Hybrid deployment strategy
Most production teams running Qwen3-VL in 2026 deploy both variants on the same infrastructure and route per request. Because the weights share an architecture, vLLM and SGLang can hot-swap between them with minimal startup cost — or you can keep both resident on a single 24-32 GB GPU.
Healthcare example. Patient-facing symptom triage hits Instruct (sub-second response over uploaded images), while internal radiology second-opinion runs on Thinking (5-10 s acceptable, audit-grade reasoning required).
E-learning example. Quick image-based MCQ grading at exam-scale volumes uses Instruct; tutor-mode worked solutions use Thinking, with the reasoning chain rendered as a teaching artifact.
Financial services example. Document classification, OCR and routing run on Instruct; due-diligence analysis and fraud-pattern surfacing run on Thinking, with reasoning chains preserved for compliance review.
Routing logic in code typically branches on a content-type or task-class tag attached to the request, with a circuit breaker that falls back to Instruct if the Thinking model's queue depth exceeds a latency budget.
Qwen3-VL-4B-Instruct — best for
- Real-time visual chat / commerce search. Sub-300 ms first-token response on a 5070 with FP8 supports interactive product-image search. Every 100 ms of added latency continues to cost roughly 1% conversion at most large retailers.
- Document and form processing. Banks and insurers report ~94% accuracy on automated KYC and mortgage-application field extraction with Qwen3-VL-4B-Instruct in production, with manual-review time reduced ~67% versus the 2024 OCR-plus-rules pipelines they replaced.
- Accessibility. Live scene description, sign and label reading, hazard alerts ("clear path ahead, stairs in 3 m") at conversational latency.
- Content moderation. A social platform processing 500K image uploads daily handles the workload on a single RTX 5090 in FP8, with ~91% accuracy on policy violations and ~73% reduction in human-moderator workload.
- Retail and warehouse. Shelf inventory counting, damaged-packaging detection, robotic-pick target identification and quality-control inspection on continuous camera feeds.
- Visual product agents. The 4B model fits comfortably alongside frontier text models on the same H100, so e-commerce assistants typically run vision through Qwen3-VL-4B-Instruct and reasoning/copy through GPT-5.5 or Claude 4.7.
Qwen3-VL-4B-Thinking — best for
- Education and tutoring. Step-by-step worked solutions over photos of homework. Universities deploying Thinking for STEM tutoring report ~34% improvement in student problem-solving skill versus answer-only systems, because the model exposes method, not just answers.
- Medical imaging triage. Structured second-opinion reasoning over X-rays, CT slices and pathology slides. Not a replacement for a radiologist, but a strong assistive layer with a defensible audit trail.
- Scientific research. Pharmaceutical and materials-science teams use Thinking to scan thousands of molecular-structure or microscopy figures from literature and surface candidates by structural similarity and documented efficacy patterns.
- Legal review. Identifying problematic clauses, cross-referencing terms across multi-page contracts, comparing redline versions, reasoning about the legal effect of specific language.
- Financial due diligence. Cross-checking figures across balance sheet, income statement and cash flow; calling out the reasoning behind each flag. VC firms report ~40% time savings on preliminary due diligence with this kind of pipeline.
- Long video review. Hours-long footage with timestamped event reasoning — security, compliance, media production highlights, lecture-video summarization.
Deployment guide
Hugging Face Transformers
pip install "transformers>=4.49" "torch>=2.5" "torchvision" "qwen-vl-utils"
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
model_instruct = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-4B-Instruct",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
model_thinking = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-4B-Thinking",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Instruct")
vLLM (recommended for production)
pip install "vllm>=0.13" "qwen-vl-utils"
from vllm import LLM, SamplingParams
llm = LLM(
model="Qwen/Qwen3-VL-4B-Instruct-FP8",
trust_remote_code=True,
gpu_memory_utilization=0.90,
dtype="auto",
)
sampling_instruct = SamplingParams(temperature=0.7, top_p=0.8, top_k=20, max_tokens=16384)
sampling_thinking = SamplingParams(temperature=1.0, top_p=0.95, top_k=20, max_tokens=40960)
llama.cpp and MLX (consumer / Apple Silicon)
# llama.cpp with the official GGUF release
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp && cmake -B build -DLLAMA_CUDA=ON && cmake --build build -j
./build/bin/llama-mtmd-cli \
-m Qwen3-VL-4B-Instruct-Q4_K_M.gguf \
--mmproj qwen3-vl-4b-mmproj.gguf \
--image ./test.jpg \
-p "Describe what you see"# MLX on Apple Silicon
pip install mlx-vlm
python -m mlx_vlm.generate \
--model mlx-community/Qwen3-VL-4B-Instruct-4bit \
--image ./test.jpg \
--prompt "Describe what you see" \
--max-tokens 512Both pipelines have first-class support for the Qwen3-VL-4B Instruct and Thinking checkpoints in 2026. MLX is typically the better choice on M-series Macs because of unified memory and Metal-tuned kernels.
Optimization techniques
- Flash Attention 2/3. 2-4x speedup on multi-image and video, with 20-30% memory savings.
- FP8 weights and KV cache. Use the official
Qwen/Qwen3-VL-4B-Instruct-FP8and-Thinking-FP8checkpoints; nearly indistinguishable from BF16 in blind comparisons. - Continuous batching. vLLM and SGLang both deliver 3-5x throughput improvements over naive sequential serving.
- Speculative decoding. Pair Qwen3-VL-4B-Instruct as a draft model when serving Qwen3.5-VL-7B for a 1.5-2x speedup with no quality regression.
Common pitfalls
- Greedy decoding with Thinking. Don't use
do_sample=Falseon the Thinking model — it disables exploration and produces shallow chains. Keep temperature 0.4-1.0. - Truncated reasoning. Setting
max_tokens=512on Thinking will cut chains mid-step. Start at 8K and tune up. - Context vs VRAM. 256K native does not mean free. Monitor KV cache and reduce context or quantize KV when you hit OOM.
- Open-ended
<think>tags. The Thinking model often emits only the closing</think>in the visible response when the chat template hides the reasoning; this is expected, not a parser bug.
Competitive positioning (April 2026)
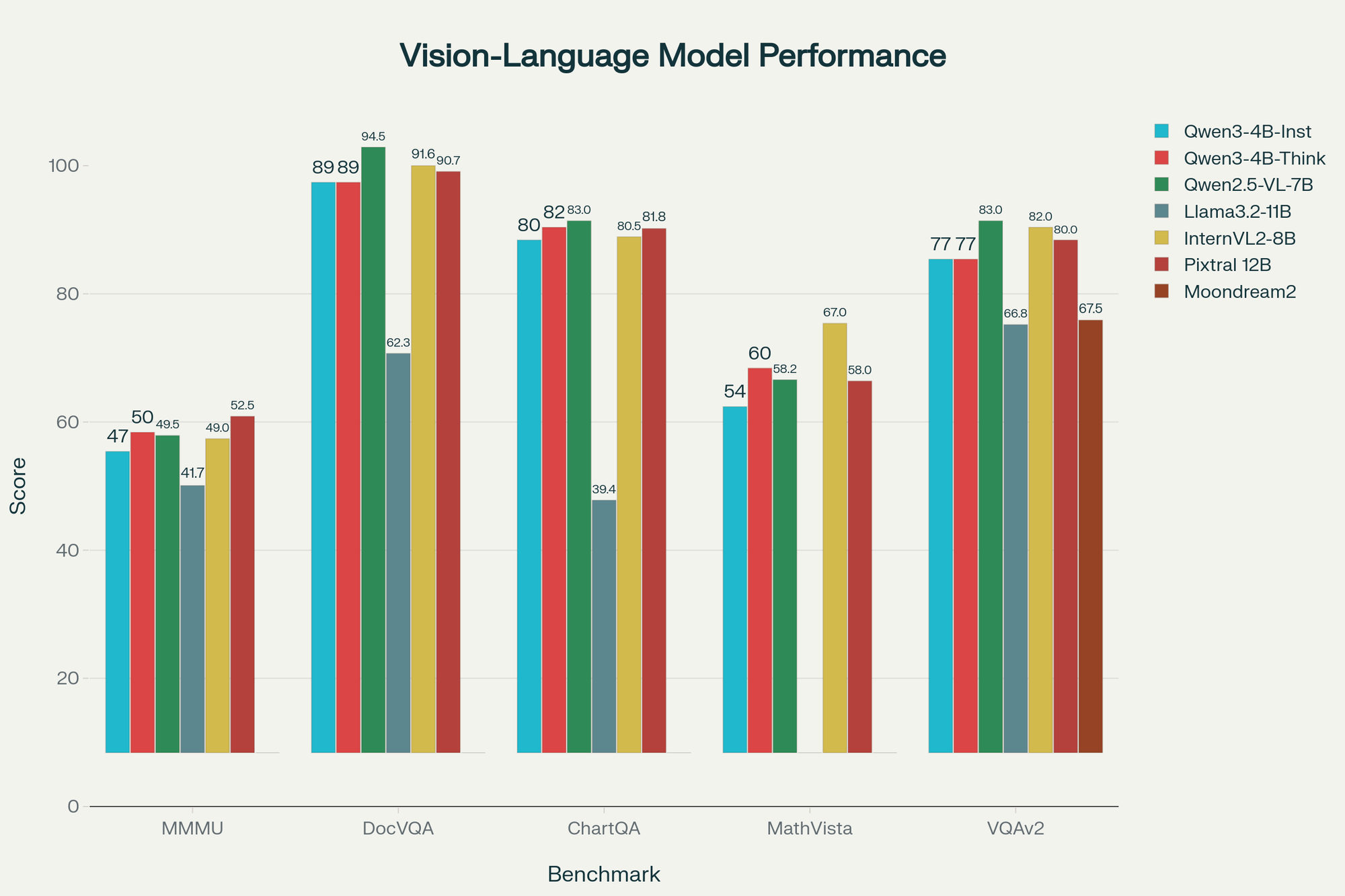
Technical specs side-by-side
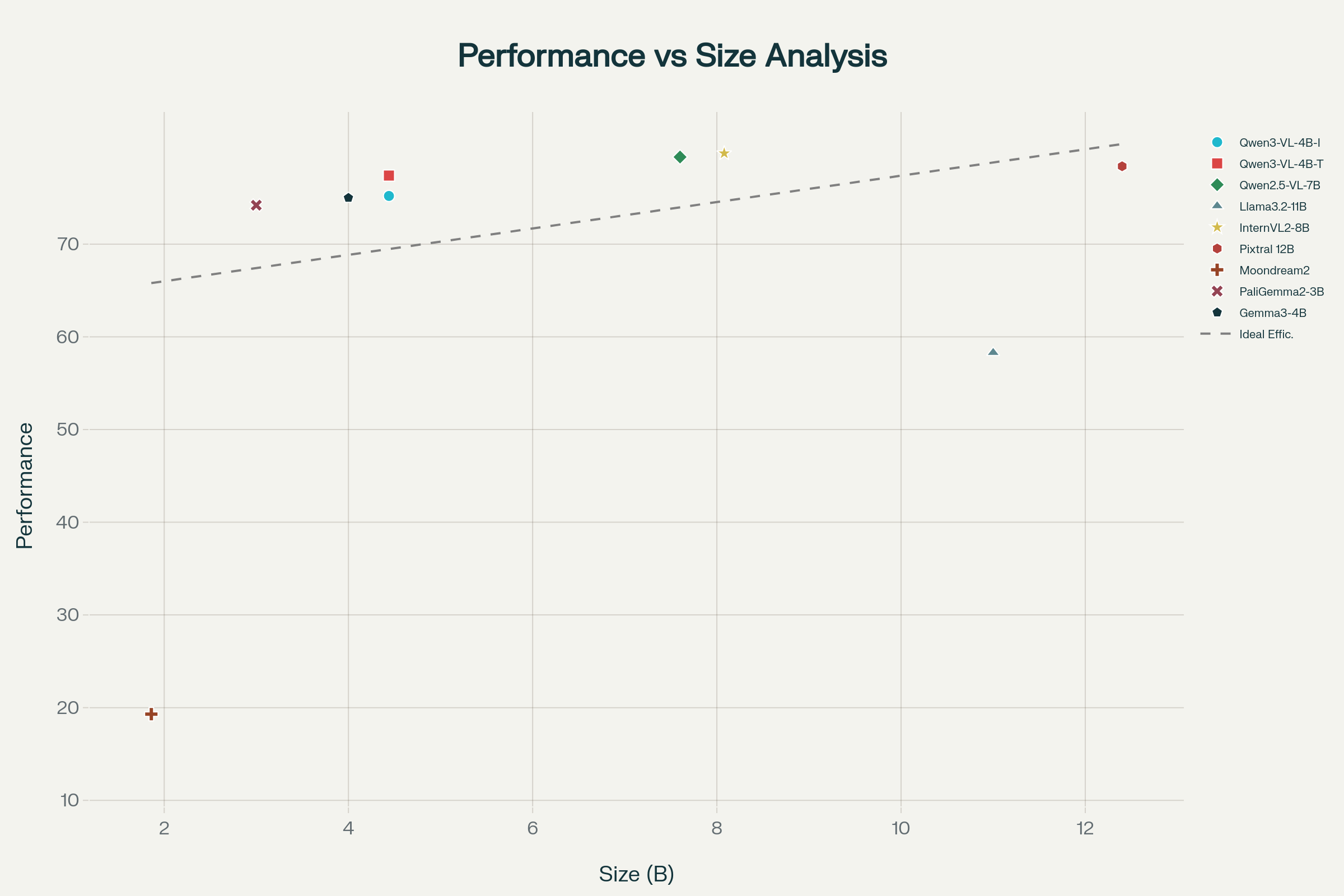
| Spec | Qwen3-VL-4B | Gemma 4 E4B | Llama 4 Scout | Pixtral 12B v2 |
|---|---|---|---|---|
| Total params | 4.44B | ~4B effective | 17B (4B active) | 12.4B |
| Native context | 256K (1M scaled) | 128K | 128K | 128K |
| Modalities | text, image, video | text, image, audio | text, image | text, image |
| OCR languages | 32 | ~20 | ~10 | ~8 |
| Reasoning variant | yes (Thinking) | prompt-only | prompt-only | no |
| License | Apache 2.0 | Gemma custom | Llama 4 community | Apache 2.0 |
| VRAM (BF16) | 10-12 GB | ~9-11 GB | 22-26 GB | 22-26 GB |
Qwen3-VL-4B vs 2026 peers
- vs Gemma 4 E4B (~4B effective). Gemma 4 adds audio input via the USM conformer encoder and ships day-zero MediaPipe / LiteRT support — better for mobile and audio-aware pipelines. Qwen3-VL-4B keeps the lead on long video, OCR breadth (32 languages), 256K-1M context, and Apache 2.0 licensing vs Gemma's custom terms.
- vs Gemma 4 31B. Different weight class — Gemma 4 31B leads at 76.9% on MMMU-Pro Vision, but at ~7x the parameters. Use Gemma 4 31B when accuracy ceiling matters and a 24-32 GB GPU is available; otherwise Qwen3-VL-4B is the better $/quality choice.
- vs Llama 4 Scout (17B-A4B MoE). Llama 4 Scout is a vision-text model only (no audio) with active params close to Qwen3-VL-4B but a larger total footprint. Qwen3-VL-4B-Thinking still leads on transparent reasoning; Llama 4 Scout edges ahead on raw English VQA.
- vs Qwen3.5-VL-7B (the natural upgrade). Qwen3.5-VL-7B improves visual grounding and benchmark scores by 4-7 points on average but doubles the parameter count and roughly doubles inference cost. Stay on 4B unless your accuracy floor demands the upgrade.
- vs Qwen2.5-VL-7B (predecessor). Qwen3-VL-4B delivers ~92-95% of Qwen2.5-VL-7B's accuracy at 58% of the params and 1.4-1.6x the throughput. Qwen2.5-VL is a maintenance-only line in 2026.
- vs Moondream 3 (~2B). Moondream 3 is the right pick on phones, microcontrollers and other extreme-edge targets. Above ~3 GB VRAM, Qwen3-VL-4B's accuracy and language coverage win decisively.
What still makes Qwen3-VL-4B special in 2026
- Efficiency at scale. 4.44B parameters delivers performance equivalent to many 7-8B-class peers, while requiring 40-50% less VRAM and running 1.5-2x faster.
- Dual-mode architecture. Instruct and Thinking share weights and tokenizer, so a single deployment can serve both with hot-swap or co-residence.
- Apache 2.0 licensing. Commercial use, modification and redistribution without royalties — still rare among the 2026 frontier-adjacent VLMs (Gemma 4 ships under Google's custom license, Llama 4 under Meta's community terms).
- Edge deployment viability. Q4_K_M variants run on phones, embedded boards and consumer GPUs as small as 6 GB; this is the smallest "real" VLM that still handles 256K context and 32-language OCR.
- Multilingual coverage. 119 text languages and 32 OCR languages remains the broadest support among open-weight 4B-class VLMs in April 2026.
- Reasoning transparency. The Thinking variant is the only mainstream 4B-class VLM that ships explicit chain-of-thought training; competitors require prompting or fine-tuning to approximate this behavior.
Cost comparison (per 1M tokens, April 2026)
| Model | Input | Output | VRAM (BF16) |
|---|---|---|---|
| Qwen3-VL-4B (3rd-party hosted) | $0.05-0.10 | $0.25-0.40 | 10-12 GB |
| Qwen3.5-VL-7B | $0.12-0.18 | $0.50-0.70 | 16-18 GB |
| Gemma 4 E4B | $0.08-0.15 | $0.30-0.50 | ~9-11 GB |
| Llama 4 Scout 17B-A4B | $0.18-0.25 | $0.70-0.90 | 22-26 GB |
| Pixtral 12B v2 | $0.20-0.30 | $0.85-1.05 | 22-26 GB |
Decision framework
Use this short routing logic:
- Pick Instruct if first-token latency under 500 ms matters, throughput is >100 RPS, outputs should be terse, or you're shipping to consumer GPUs / mobile.
- Pick Thinking if accuracy and audit trails matter (medical, legal, finance), tasks are multi-step, or you need transparent reasoning for end users.
- Pick both in production: route customer-facing traffic to Instruct, route analyst / reviewer traffic to Thinking. The model weights hot-swap cleanly because the architecture is identical.
End-to-end examples
Example 1 — receipt extraction (Instruct)
A typical accounts-payable pipeline takes a phone-camera photo of a receipt and produces a structured JSON record. With Qwen3-VL-4B-Instruct on FP8:
from PIL import Image
import json
from vllm import LLM, SamplingParams
llm = LLM(model="Qwen/Qwen3-VL-4B-Instruct-FP8", trust_remote_code=True)
prompt = (
"Extract this receipt as JSON with keys: merchant, date_iso, "
"subtotal, tax, total, currency, line_items[]. Only return JSON."
)
messages = [{"role": "user", "content": [
{"type": "image", "image": Image.open("receipt.jpg")},
{"type": "text", "text": prompt},
]}]
out = llm.chat(messages, SamplingParams(temperature=0.0, max_tokens=1024))
record = json.loads(out[0].outputs[0].text)End-to-end latency on a 5070 with FP8: ~600-900 ms for a single receipt, dominated by image-encoding time. Throughput at batch size 8 reaches ~25-30 receipts/sec.
Example 2 — radiology second-opinion (Thinking)
The Thinking model is set up to produce a structured reasoning chain that a radiologist can audit:
prompt = """Analyze this chest X-ray. Walk through:
1. Pneumothorax check
2. Cardiac silhouette
3. Lung-field opacities (left vs right)
4. Pleural effusion
5. Differential considerations
End with a bullet list of findings and a confidence note."""
out = llm.chat(messages, SamplingParams(
temperature=1.0, top_p=0.95, top_k=20, max_tokens=8192,
))The model emits a <think> block walking through each numbered step with explicit visual evidence, then a clean findings list. Round-trip on a 5070 in BF16: ~6-12 s per image, perfectly acceptable for a non-real-time second-opinion lane.
Example 3 — long video summary (Thinking)
Hour-long lecture summarization using the 256K context:
prompt = """Summarize this 60-minute lecture. Produce:
- 5-8 timestamped section headings
- Key claims per section with evidence shown on slide
- Open questions raised but not answered
"""Run at 1 fps key-frame sampling; the Thinking model uses its temporal alignment to anchor section boundaries to actual visual transitions. Output is typically 800-1,500 tokens of structured markdown plus a <think> block tracing the reasoning. Total wall-clock on an H100 with FP8: 30-90 s for a 60-minute video, depending on slide-change density.
Security and safety considerations
Operationally relevant gotchas as of May 2026:
- Prompt injection via images. Both variants are vulnerable to instructions hidden in images (low-contrast text, QR codes, steganographic prompts). Sanitize at the pipeline layer; assume the model will follow image-embedded text.
- PII exposure in OCR. 32-language OCR is excellent at extracting names, ID numbers and license plates. Add redaction or output-filtering for any user-facing OCR product.
- Reasoning trace leakage. The Thinking variant's
<think>traces can quote training data more verbatim than the final answer. Strip traces before logging if your privacy posture requires it. - Jailbreak via reasoning. Adversarial prompts that ask the Thinking model to "reason about whether" something is acceptable can occasionally produce policy-relaxed output. Apply the same content filters to
<think>output you would to the final answer. - Medical / legal disclaimer. Apache 2.0 doesn't carry liability waivers your domain might need. If you ship in regulated verticals, run outputs through a domain-specific reviewer model and keep a human in the loop.
Current limitations (April 2026)
- Reasoning chain length still capped around 40K tokens output; problems requiring 50+ explicit steps push that ceiling.
- Hour-plus video at 256K context still demands 20-40 GB VRAM depending on resolution; not yet practical on single-GPU consumer hardware.
- Pixel-precise grounding (bounding boxes, segmentation masks) lags specialized models like Grounding DINO 2 and SAM 3.
- Handwritten math notation remains the weakest OCR axis.
- No 4B successor yet. Qwen3.5-VL skipped the 4B size in its 2026 launch; Qwen3-VL-4B is the recommended 4B-tier model and is likely to remain so until a Qwen 3.6-VL release.
Fine-tuning and customization
Both 4B variants are first-class citizens in the 2026 fine-tuning ecosystem. A few practical notes for teams adapting them to a domain:
LoRA and QLoRA
Low-rank adaptation (LoRA, rank 16-64) on an RTX 5070 fits comfortably in 12 GB VRAM at BF16 with batch size 1-2 and gradient checkpointing. QLoRA (4-bit base + LoRA adapter) drops the requirement to ~6 GB and runs on any 8 GB consumer GPU. Tools that support Qwen3-VL natively in 2026: peft 0.14+, unsloth, axolotl, llama-factory.
Full fine-tune considerations
A full fine-tune of either 4B variant fits on a single H100 80 GB with batch sizes appropriate for instruction-following workloads. Most teams should not need this — LoRA recovers ~95% of the gain at a fraction of the cost.
Don't fine-tune away the thinking
If you fine-tune the Thinking variant on data that doesn't include <think> traces, you will degrade the reasoning behavior. Either preserve traces in your dataset (synthesizing them with a teacher model is fine) or fine-tune the Instruct variant instead.
Upgrade path from Qwen3-VL-4B
If you're already running Qwen3-VL-4B in production and considering whether to move up the stack in 2026, the realistic options are:
Up to Qwen3.5-VL-7B
The natural next step. ~4-7 benchmark points across most evaluations, better visual grounding, same training philosophy and chat template family, drop-in replacement for most stacks. Costs roughly 1.6-1.8x the inference compute of Qwen3-VL-4B. Recommended when accuracy floor matters and a 16-24 GB GPU is already in your envelope.
Up to Qwen3-VL-30B-A3B
The MoE variant — 30B total parameters but only 3B active per token. Sits between 4B-dense and 7B-dense in compute cost, but with substantially better accuracy on hard reasoning. The right choice when you need accuracy closer to 30B-class but want to keep latency and per-token cost reasonable. Requires more VRAM than 4B-dense (need to hold all experts in memory) but throughput is excellent.
Up to Qwen3-VL-235B-A22B
Frontier of the open-weights vision space. 22B active params per token in an MoE configuration; best-in-class on every public 2026 benchmark for open weights. Requires multi-GPU or H100/H200/B200 hardware to host. Use only when you have datacenter-class infra and the accuracy delta justifies the operational complexity.
Cross-grade to Gemma 4 E4B
Same parameter class, but adds audio input via the USM conformer encoder and ships LiteRT/MediaPipe bindings for Android and iOS day-zero. Choose Gemma 4 E4B if your roadmap includes voice or mobile deployment. Stay on Qwen3-VL-4B if you need long video, OCR breadth, or transparent reasoning.
Cross-grade to Llama 4 Scout (17B-A4B MoE)
Active-parameter count similar to Qwen3-VL-4B, but with a larger total memory footprint (22-26 GB). Stronger on raw English VQA, weaker on multilingual and on transparent reasoning. Choose Scout if Meta-ecosystem integration matters or if you're already running Llama 4 text models on the same node.
Conclusion
Qwen3-VL-4B-Instruct and Qwen3-VL-4B-Thinking remain, in April 2026, the best 4B-class open-weights vision-language pair: Apache 2.0, 256K-1M context, 32-language OCR, native video temporal reasoning, and a clean Instruct/Thinking split that maps cleanly onto real product needs. Instruct ships speed and cost; Thinking ships transparent reasoning and accuracy. They run on consumer hardware, deploy through standard vLLM / SGLang / llama.cpp stacks, and are likely to stay the default 4B vision model until a Qwen 3.6-VL release.
Related on Codersera
- DeepSeek V4 vs Claude vs GPT-5: AI coding model comparison (2026) — pillar comparing the 2026 frontier coding models you'll most often pair with Qwen3-VL.
- Qwen3-VL-30B-A3B-Thinking: complete deployment guide — the natural upgrade path when you outgrow the 4B tier.
- Qwen3-VL-8B Instruct vs Thinking — same Instruct/Thinking framing one weight class up.
- Gemma vs Qwen — open-source comparison — context for the Gemma 4 alternative discussed above.