
Last updated: May 1, 2026.
Qwen3-VL-30B-A3B-Thinking represents a groundbreaking achievement in artificial intelligence, offering unprecedented multimodal reasoning capabilities. As part of Alibaba's Qwen3-VL series originally released in September 2025, this model remains a strong vision-language workhorse in the Qwen lineup as of 2026.
With its unique "thinking mode" architecture and sophisticated visual understanding capabilities, it's designed to handle complex reasoning tasks that seamlessly combine text, images, and video processing.
What sets this model apart is its Mixture-of-Experts (MoE) architecture, featuring 30.5 billion total parameters while activating only 3.3 billion during inference. This innovative approach delivers performance rivaling much larger models while maintaining computational efficiency that makes local deployment feasible.
The model excels at multimodal reasoning, spatial understanding, video analysis, and agent interaction tasks—making it an ideal choice for developers, researchers, and organizations seeking cutting-edge AI capabilities.
What changed in this 2026 refresh: Updated tooling baselines (vLLM 0.20+, transformers 4.48+), refreshed 2026 hardware tier guidance, and added 2026 competitive context (DeepSeek V4, Qwen 3.5-VL family, GPT-4o successors).
Want the full picture? Read our continuously-updated Qwen 3.5 Complete Guide (2026) — flavors, licensing, benchmarks, and on-device usage.
Understanding the Model Architecture and Capabilities
1. Core Technical Specifications
Qwen3-VL-30B-A3B-Thinking operates on a sophisticated Mixture-of-Experts architecture that maximizes efficiency while maintaining exceptional performance. The model contains 30.5 billion total parameters with only 3.3 billion activated during inference, utilizing 128 experts with 8 activated at any given time.
This design employs 48 layers with Grouped Query Attention (GQA) featuring 32 query heads and 4 key/value heads.The model supports a native 256K context length that can be extended up to 1 million tokens, enabling processing of extensive documents, long videos, and complex multimodal inputs.
2. Revolutionary Architectural Enhancements
Three key architectural innovations distinguish Qwen3-VL-30B-A3B-Thinking from its predecessors:
- Interleaved-MRoPE provides full-frequency allocation across time, width, and height dimensions through robust positional embeddings, significantly enhancing long-horizon video reasoning capabilities.
- DeepStack integration fuses multi-level Vision Transformer (ViT) features to capture fine-grained details while sharpening image-text alignment, resulting in superior visual understanding.
- Text-Timestamp Alignment moves beyond traditional T-RoPE to enable precise, timestamp-grounded event localization for stronger video temporal modeling.
3. The "Thinking Mode" Revolution
The model's most distinctive feature is its dedicated reasoning mode. Unlike hybrid approaches, Qwen3-VL-30B-A3B-Thinking operates in pure reasoning mode, automatically wrapping its internal reasoning process in <think>...</think> blocks.
This approach allows the model to perform step-by-step analysis before providing final answers, making it exceptionally capable for complex problem-solving tasks.
The thinking mechanism follows a structured flow: User Input → Auto-added <think> tag → Internal reasoning process → </think> tag → Final answer. This separation ensures that users receive both the reasoning process and the conclusive result, providing transparency in the model's decision-making.
Comprehensive Installation and Setup Guide
1. System Requirements and Hardware Considerations
Before installing Qwen3-VL-30B-A3B-Thinking, understanding hardware requirements is crucial for optimal performance. The model's MoE architecture allows it to run on systems with 32GB RAM when using quantized versions, achieving impressive speeds of 100+ tokens per second on high-end Apple Silicon (M4 Max in 2025; M5 Max / M5 Ultra workstations in 2026 push this further).
For GPU-based deployment in 2026, the practical hardware tiers are:
- Single-card (consumer) tier: RTX 4090 (24 GB) and RTX 5090 (32 GB) — viable only with 4-bit AWQ / GGUF quantization and short video clips.
- Single-card (workstation) tier: RTX 6000 Ada / RTX PRO 6000 Blackwell (48–96 GB) — comfortable for BF16 with image and short-video workloads.
- Datacenter tier: H100 / H200 (80–141 GB) and B200 (192 GB) — required for full BF16 long-video and 1M-token context.
Memory requirements still vary significantly based on precision and context length:
- BF16 precision with 15-second video processing requires approximately 78.85 GB of GPU memory
- 30-second video processing increases requirements to 88.52 GB
- 60-second video processing demands 107.74 GB
- 120-second video processing requires 144.81 GB
2. Essential Dependencies Installation
Setting up the proper environment is critical for successful deployment. As of May 2026, vLLM 0.20+ and transformers 4.48+ are the recommended baselines (older 0.11.x branches still load the model but miss multimodal performance fixes shipped through late 2025 and early 2026). Create a fresh Python environment and install the required dependencies:
pip install -U pip uv
# Install vLLM >= 0.20.0 for efficient inference (2026 baseline)
uv pip install -U "vllm>=0.20.0"
# Install Qwen-VL utility library for offline inference
uv pip install qwen-vl-utils==0.0.14
# Install transformers >= 4.48 (or from source for bleeding-edge fixes)
pip install -U "transformers>=4.48.0"
# or: pip install git+https://github.com/huggingface/transformersFor PyTorch and transformers compatibility, PyTorch 2.5+ with CUDA 12.4+ is the practical 2026 baseline; FlashAttention-3 is recommended on Hopper/Blackwell GPUs.
3. Model Download and Storage
The model can be obtained through multiple channels depending on your preferred platform:
Hugging Face Download:
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-30B-A3B-Thinking")ModelScope Download:
from modelscope import snapshot_download
snapshot_download('Qwen/Qwen3-VL-30B-A3B-Thinking', cache_dir="your_local_path")Quantized Versions are available for reduced memory footprint, with AWQ 4-bit quantization reducing storage to approximately 17 GB while maintaining performance.
Deployment Strategies: From Local to Cloud
1. Local Deployment with Transformers
For direct local deployment using transformers, the following implementation provides a solid foundation:
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor
import torch
# Load model with flash attention for better performance
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-30B-A3B-Thinking")
# Example usage for image analysis
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "path/to/your/image.jpg"},
{"type": "text", "text": "Analyze this image and explain the key elements."}
]
}
]
# Process and generate response
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
generated_ids = model.generate(**inputs, max_new_tokens=2048)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)2. vLLM Deployment for Production
For production environments requiring high throughput and efficient resource utilization, vLLM 0.20+ provides the optimal deployment strategy:
CONTEXT_LENGTH=32768
vllm serve \
Qwen/Qwen3-VL-30B-A3B-Thinking \
--served-model-name Qwen3-VL-Thinking \
--swap-space 4 \
--max-num-seqs 8 \
--max-model-len $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 2 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000This configuration enables OpenAI-compatible API endpoints that can be integrated with existing applications seamlessly. The tensor-parallel-size parameter should be adjusted based on your available GPU configuration.
3. Ollama Integration for Simplified Deployment
Ollama provides perhaps the most user-friendly deployment option for local development. Vision support for Qwen3-VL has matured through 2026; for the latest tags check the Ollama library, but the base Qwen3-30B-A3B models continue to work as a fallback:
bashollama pull qwen3:30b-a3bollama run qwen3:30b-a3b "Hello, how can you help me today?"
For full vision capabilities, users often combine Ollama with custom implementations or use vLLM-based deployments where Qwen3-VL multimodal support is most complete.
Advanced Configuration and Optimization
1. Generation Parameters for Thinking Mode
Thinking mode requires specific generation settings to function optimally. Unlike traditional models, greedy decoding breaks thinking mode and should be avoided. The recommended configuration includes:
- Temperature: 0.6 (allows creative reasoning)
- Top-P: 0.95 (maintains coherence)
- Top-K: 20 (controls vocabulary selection)
- Max tokens: 32,768 (accommodates reasoning chains)
- Enable sampling: Critical for thinking mode operation
generation_config = {
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_new_tokens": 32768,
"do_sample": True, # Never use greedy decoding
}
outputs = model.generate(**inputs, **generation_config)2. Memory Optimization Techniques
For systems with limited GPU memory, several optimization strategies can improve performance:
Quantization Options:
- FP8 quantization reduces memory by approximately 50% with minimal performance loss
- 4-bit AWQ quantization can reduce storage to ~17GB while maintaining quality
- GGUF formats enable CPU inference for systems without sufficient GPU memory
Memory-Efficient Loading:
# Load with 8-bit quantization
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
load_in_8bit=True,
device_map="auto"
)
# Or use FP8 for better efficiency
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking-FP8",
dtype=torch.float8_e5m2,
device_map="auto"
)3. Context Length Optimization
The model's 256K native context can be extended to 1M tokens for extremely long inputs. However, this comes with increased memory requirements:
# Configure for long context
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
max_length=262144 # Use full 256K context
)Practical Implementation Examples
1. Image Analysis and Description
One of the model's strongest capabilities lies in comprehensive image analysis. Here's a practical implementation for detailed image processing:
def analyze_image(image_path, question="Analyze this image in detail"):
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": question}
]
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
# Generate with thinking mode parameters
generated_ids = model.generate(
**inputs,
max_new_tokens=2048,
temperature=0.6,
top_p=0.95,
do_sample=True
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)[0]
return response
# Usage example
result = analyze_image("screenshot.png", "What UI elements are visible and how would you interact with them?")
print(result)2. Video Analysis and Temporal Understanding
The model excels at video understanding with its enhanced temporal modeling capabilities:
def analyze_video(video_path, query="Describe the key events in this video"):
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": video_path},
{"type": "text", "text": query}
]
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
# Video analysis often requires longer generation
generated_ids = model.generate(
**inputs,
max_new_tokens=4096,
temperature=0.6,
top_p=0.95,
do_sample=True
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
return processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True)[0]3. Document Processing and OCR
With support for 32 languages and enhanced OCR capabilities, the model handles complex document processing tasks:
def process_document(image_path, language="English"):
prompt = f"""
Extract and transcribe all text from this document.
Pay attention to:
1. Maintaining original formatting
2. Preserving table structures
3. Identifying headers and sections
4. Note any visual elements (charts, diagrams)
Language: {language}
"""
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": prompt}
]
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
generated_ids = model.generate(
**inputs,
max_new_tokens=8192, # Longer for complex documents
temperature=0.3, # Lower temperature for accuracy
top_p=0.9,
do_sample=True
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
return processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True)[0]4. Code Generation from Visual Mockups
The model's visual coding capabilities enable generation of HTML/CSS/JavaScript from images or mockups:
def generate_code_from_mockup(image_path, framework="HTML/CSS"):
prompt = f"""
Generate {framework} code based on this UI mockup. Include:
1. Semantic HTML structure
2. CSS styling to match the design
3. Responsive design considerations
4. Any interactive elements with JavaScript if needed
Provide clean, well-commented code that accurately represents the design.
"""
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": prompt}
]
}
]
# Process with longer context for complex code generation
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
generated_ids = model.generate(
**inputs,
max_new_tokens=6144,
temperature=0.4,
top_p=0.9,
do_sample=True
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
return processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True)[0]Performance Benchmarks and Comparisons
1. Multimodal Reasoning Excellence
Qwen3-VL-30B-A3B-Thinking demonstrates exceptional performance across diverse multimodal benchmarks. In Math and STEM evaluations, the model achieves remarkable scores, often outperforming larger competitors:
- MMMU-Pro overall: 60.5, competing closely with models like InternVL-3.5-241B-A28B
- MathVista mini: 80.0, demonstrating strong mathematical visual reasoning
- MATH-Vision full: 62.9, showing excellent mathematical problem-solving
The model's thinking capabilities provide a significant advantage, with the thinking version outperforming the instruct baseline by 4.4 points on Math and STEM benchmarks.
2. Competitive Positioning (2026)
By 2026, the multimodal landscape has expanded considerably. Qwen3-VL-30B-A3B-Thinking still holds its ground impressively against the current commercial frontier — including OpenAI's GPT-4o successors, Anthropic's Claude 3.7/4 family, and Google Gemini 2.5 — particularly on document, math, and agentic GUI tasks. On the open-weights side, the most relevant 2026 alternatives are:
- Qwen 3.5-VL family (released in early 2026) — incremental improvements in long-video reasoning and agent tool use; worth evaluating if you can absorb a model swap.
- DeepSeek V4 and the DeepSeek-VL2 line — strong text reasoning with competitive vision support, especially attractive on cost/quality for chat-heavy workloads.
- InternVL 3.x — still the closest large-scale open VLM competitor on raw benchmarks.
The model offers a 262K context window which remains generous compared to many commercial entry tiers, while its open-source license continues to provide value for organizations requiring model customization and local deployment.
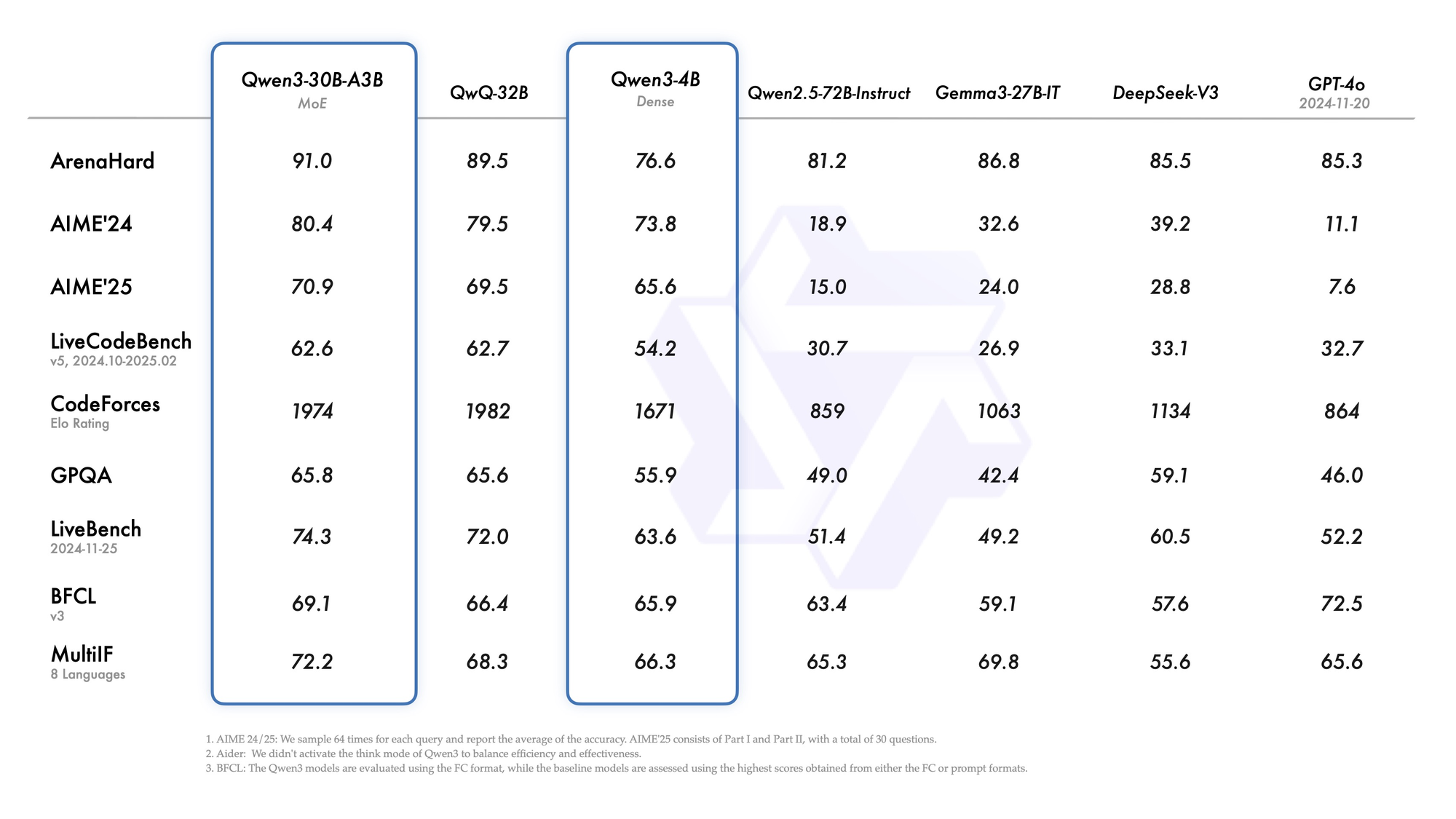
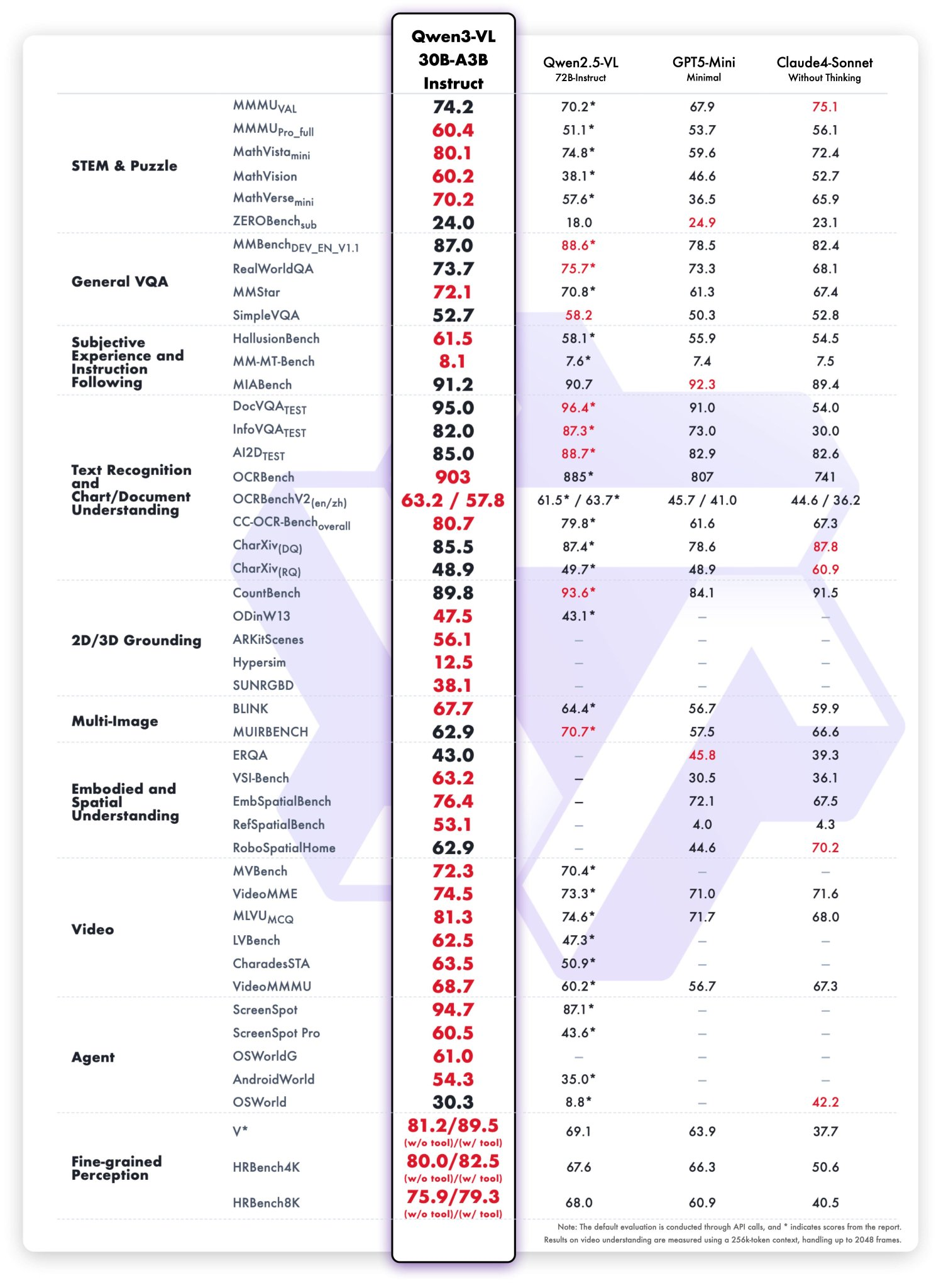
Against Claude and Gemini models, Qwen3-VL-30B-A3B-Thinking often demonstrates superior performance in specialized tasks like document processing, mathematical reasoning, and code generation. The model's ability to maintain consistent performance while using only 3.3B active parameters showcases the efficiency of its MoE architecture.
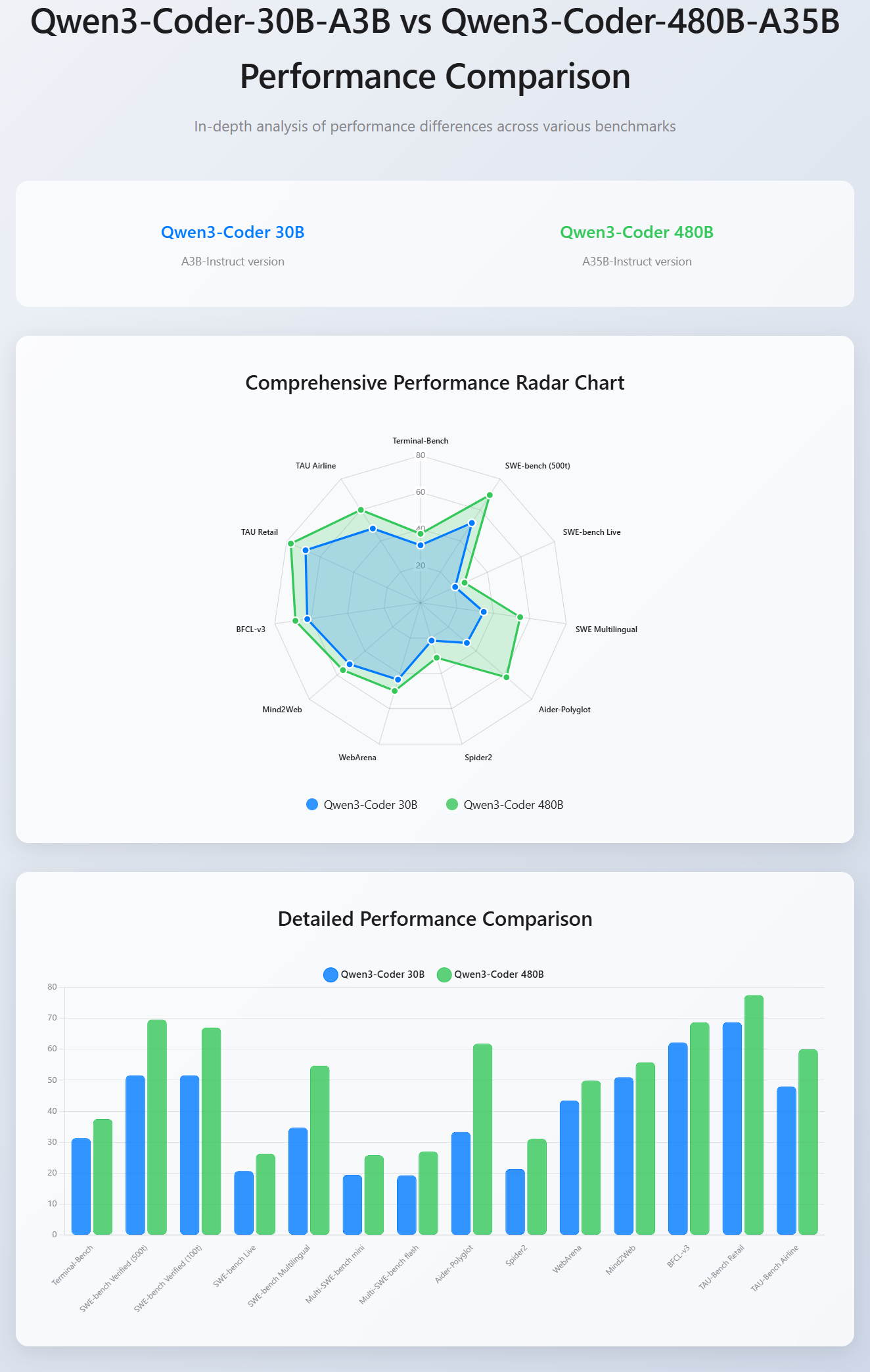
Performance Comparison:
Qwen3-Coder-30B-A3B vs. Qwen3-Coder-480B-A35B
Speed and Efficiency Metrics
Real-world performance testing reveals impressive throughput characteristics:
- 34 tokens/second on high-end consumer GPUs (RX 7900 XTX); 2026 RTX 5090 / RX 9000-series setups push this 1.5-2x with the same quantization.
- 100+ tokens/second on optimized Hopper / Blackwell hardware configurations
- Efficient memory utilization allowing operation on systems with 32GB RAM
The model's quantized versions maintain performance while reducing resource requirements, with FP8 quantization providing an optimal balance between speed and quality.
Advanced Use Cases and Applications
1. Visual Agent and GUI Automation
One of the model's most innovative applications involves visual agent capabilities. The model can recognize UI elements, understand their functions, and provide instructions for automation tasks:
def gui_automation_analysis(screenshot_path):
prompt = """
Analyze this GUI screenshot and provide:
1. Identification of all interactive elements
2. Their likely functions and purposes
3. Step-by-step instructions for common tasks
4. Accessibility considerations
5. Potential automation opportunities
Focus on actionable insights for GUI automation.
"""
return analyze_image(screenshot_path, prompt)2. Scientific and Technical Document Analysis
The model excels at processing complex scientific documents, technical manuals, and research papers:
def analyze_scientific_document(document_image_path):
prompt = """
Analyze this scientific document page. Identify:
1. Main concepts and theories presented
2. Mathematical formulas and their meanings
3. Diagrams, charts, and their relationships to the text
4. Key findings or conclusions
5. References to other research
Provide a comprehensive academic summary.
"""
return process_document(document_image_path, "Scientific/Technical")3. Multilingual Content Processing
With support for 32 languages, the model handles diverse international content:
def multilingual_content_analysis(image_path, target_language="English"):
prompt = f"""
Process this multilingual content:
1. Identify all languages present
2. Translate content to {target_language}
3. Preserve formatting and structure
4. Note any cultural or linguistic nuances
5. Highlight any translation challenges
"""
return process_document(image_path, target_language)4. Educational Content Creation
The model's reasoning capabilities make it excellent for creating educational materials:
def create_educational_content(concept_image_path, grade_level="high school"):
prompt = f"""
Based on this image, create educational content for {grade_level} students:
1. Explain the key concepts shown
2. Provide step-by-step learning objectives
3. Suggest practical exercises or questions
4. Include real-world applications
5. Identify prerequisite knowledge needed
Make the content engaging and age-appropriate.
"""
return analyze_image(concept_image_path, prompt)Troubleshooting and Common Issues
1. Memory Management Problems
Out-of-memory errors are common when first deploying the model. Solutions include:
Reduce Precision:
# Use FP16 instead of BF16 for lower memory usage
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
torch_dtype=torch.float16,
device_map="auto"
)Enable CPU Offloading:
# Offload some layers to CPU
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
device_map="auto",
max_memory={0: "20GB", "cpu": "30GB"}
)2. Generation Quality Issues
Poor response quality often stems from incorrect generation parameters:
For Thinking Mode:
- Never use greedy decoding (
do_sample=False) - Maintain temperature between 0.4-0.8
- Use appropriate top-p values (0.9-0.95)
- Provide sufficient max_tokens for reasoning chains
For Factual Tasks:
- Lower temperature (0.1-0.3) for accuracy
- Higher top-k values for consistency
- Shorter max_tokens for concise responses
3. Context Length Limitations
When processing very long inputs, consider these strategies:
Chunking Approach:
def process_long_content(content, chunk_size=200000):
chunks = [content[i:i+chunk_size] for i in range(0, len(content), chunk_size)]
results = []
for chunk in chunks:
result = model.process(chunk)
results.append(result)
return combine_results(results)Hierarchical Processing:
def hierarchical_analysis(long_video_path):
# First, get overview
overview = analyze_video(long_video_path, "Provide a brief overview of this video")
# Then, detailed analysis of key segments
segments = extract_key_segments(overview)
detailed_analyses = [analyze_segment(seg) for seg in segments]
return combine_hierarchical_results(overview, detailed_analyses)4. Platform-Specific Issues
vLLM Deployment Problems:
- Use vLLM >= 0.20.0 in 2026 (older 0.11.x will load but lacks current multimodal optimizations)
- Check CUDA compatibility (CUDA 12.4+ recommended)
- Verify tensor-parallel-size matches GPU count
- Enable trust-remote-code for custom models
Transformers Integration Issues:
- Use transformers >= 4.48 (or install from source) for the latest multimodal fixes
- Check PyTorch version compatibility (2.5+ recommended)
- Ensure flash-attention-2 (or FlashAttention-3 on Hopper/Blackwell) for performance
Best Practices and Optimization Tips
1. Prompt Engineering for Vision-Language Tasks
Effective prompting significantly impacts model performance. Structure prompts with clear sections:
def create_structured_prompt(task_type, specific_requirements):
base_template = """
Task: {task_type}
Requirements:
{specific_requirements}
Please provide:
1. [Primary analysis]
2. [Secondary insights]
3. [Actionable recommendations]
Focus on accuracy and detailed reasoning.
"""
return base_template.format(
task_type=task_type,
specific_requirements=specific_requirements
)2. Batch Processing for Efficiency
For processing multiple items, implement efficient batching:
def batch_image_analysis(image_paths, batch_size=4):
results = []
for i in range(0, len(image_paths), batch_size):
batch = image_paths[i:i+batch_size]
batch_messages = []
for path in batch:
batch_messages.append([{
"role": "user",
"content": [
{"type": "image", "image": path},
{"type": "text", "text": "Analyze this image"}
]
}])
# Process batch together for efficiency
batch_results = process_batch(batch_messages)
results.extend(batch_results)
return results3. Monitoring and Performance Tracking
Implement comprehensive monitoring for production deployments:
import time
import logging
def monitored_inference(inputs, **generation_kwargs):
start_time = time.time()
try:
results = model.generate(**inputs, **generation_kwargs)
inference_time = time.time() - start_time
logging.info(f"Inference completed in {inference_time:.2f}s")
return results
except Exception as e:
logging.error(f"Inference failed: {str(e)}")
raise4. Resource Management
Optimize resource usage through careful management:
import gc
import torch
def cleanup_resources():
"""Clean up GPU memory between large operations"""
gc.collect()
torch.cuda.empty_cache()
def resource_aware_processing(large_input_list):
results = []
for i, input_item in enumerate(large_input_list):
result = model.process(input_item)
results.append(result)
# Clean up every 10 items
if i % 10 == 0:
cleanup_resources()
return resultsFuture Developments and Roadmap
1. Model Evolution Trajectory
The Qwen3-VL series has continued to evolve, with the Qwen 3.5-VL family arriving in early 2026 and Qwen-team teasing further iterations. Themes for the next generation include:
- Enhanced Context Length: Extending beyond the current 1M token capability for even longer document processing.
- Improved Multimodal Fusion: Better integration between vision, text, and potential audio modalities.
- Efficiency Optimizations: Further improvements in the MoE architecture to reduce computational requirements while maintaining performance.
2. Community Contributions and Ecosystem
The open-source nature of Qwen3-VL-30B-A3B-Thinking has fostered a vibrant community contributing to its development. Community efforts include:
- Quantization Improvements: Ongoing work on more efficient quantization methods
- Platform Integration: Extended support for various deployment platforms
- Specialized Fine-tuning: Domain-specific adaptations for particular use cases
Integration Possibilities
Future integration opportunities include:
- API Standardization: Better compatibility with existing OpenAI-style APIs
- Cloud Platform Support: Enhanced support for major cloud providers
- Edge Deployment: Optimizations for mobile and edge computing scenarios
FAQs
1. What is Qwen3-VL-30B-A3B-Thinking and how does it differ from other AI models?
Qwen3-VL-30B-A3B-Thinking is Alibaba's advanced vision-language model featuring 30.5 billion parameters with a unique Mixture-of-Experts (MoE) architecture that activates only 3.3 billion parameters during inference. Unlike traditional models, it operates in pure "thinking mode," automatically wrapping internal reasoning in <think>...</think> blocks, providing unprecedented transparency in AI decision-making processes. 2. What are the minimum hardware requirements to run Qwen3-VL-30B-A3B-Thinking locally?
The model can run on systems with 32GB RAM when using quantized versions, achieving speeds of 100+ tokens per second on high-end Apple Silicon (M4 Max and the 2026 M5 generation). For GPU deployment, memory requirements vary by precision: BF16 precision requires approximately 78.85 GB for 15-second video processing, while 4-bit AWQ quantization reduces storage to ~17GB while maintaining quality.
3. How do I install and deploy Qwen3-VL-30B-A3B-Thinking on my system?
Installation requires Python with specific dependencies: install vLLM >= 0.20.0 (2026 baseline), qwen-vl-utils==0.0.14, and transformers >= 4.48 (or from source). For local deployment, use Qwen3VLMoeForConditionalGeneration.from_pretrained() with appropriate device mapping. For production environments, vLLM offers optimal performance with tensor-parallel deployment options.
4. What makes the "thinking mode" unique and how should I configure it properly?
The thinking mode automatically generates step-by-step reasoning before providing final answers, unlike hybrid approaches that require manual activation. Critical configuration requirements include: never use greedy decoding (do_sample=False), maintain temperature between 0.4-0.8, use top-p values of 0.9-0.95, and provide sufficient max_tokens for reasoning chains. The model automatically adds <think> tags, with outputs typically showing only the closing </think> tag, which is normal behavior.
5. Can Qwen3-VL-30B-A3B-Thinking process both images and videos effectively?
Yes, the model excels at both image and video analysis with enhanced temporal modeling capabilities. It supports video processing up to 120 seconds with advanced features like Text-Timestamp Alignment for precise event localization and Interleaved-MRoPE for long-horizon video reasoning.
6. What are the performance benchmarks compared to GPT-4 and other commercial models?
Qwen3-VL-30B-A3B-Thinking achieves competitive performance with 60.5 on MMMU-Pro, 80.0 on MathVista mini, and 62.9 on MATH-Vision full. The thinking version outperforms the instruct baseline by 4.4 points on Math and STEM benchmarks. Compared to GPT-4o mini, it offers a larger 262K context window versus 128K, and remains competitive against 2026 alternatives like DeepSeek V4 and the Qwen 3.5-VL family on document and math-vision tasks.
7. How can I optimize memory usage and improve performance for large-scale deployment?
Memory optimization strategies include using quantization (FP8 reduces memory by ~50%, 4-bit AWQ to ~17GB), enabling CPU offloading for some layers, and implementing batch processing for efficiency. For production deployment, configure vLLM with appropriate tensor-parallel-size, gpu-memory-utilization settings, and consider using quantized versions like GGUF formats for CPU inference on systems without sufficient GPU memory.
8. What are the most common troubleshooting issues and their solutions?
Common issues include out-of-memory errors (solved by reducing precision or enabling CPU offloading), poor generation quality (ensure proper temperature settings and avoid greedy decoding), and context length limitations (use chunking or hierarchical processing approaches). Platform-specific problems often involve vLLM version compatibility (use >= 0.20.0 in 2026), CUDA compatibility checks (12.4+), and ensuring trust-remote-code is enabled for custom models.
9. What real-world applications is Qwen3-VL-30B-A3B-Thinking best suited for?
The model excels in scientific document analysis, GUI automation and visual agent tasks, multilingual content processing (32 languages), educational content creation, and technical documentation processing. Its thinking capabilities make it ideal for complex reasoning tasks requiring transparency, such as medical diagnosis support, legal document analysis, code generation from visual mockups, and comprehensive video analysis for security or educational purposes.
10. How does the model compare in terms of cost-effectiveness and deployment options?
As an open-source model, Qwen3-VL-30B-A3B-Thinking offers significant cost advantages over commercial alternatives while providing comparable performance. The MoE architecture's efficiency (activating only 3.3B of 30.5B parameters) reduces computational costs significantly.
Conclusion
Qwen3-VL-30B-A3B-Thinking represents a pivotal advancement in multimodal AI, combining sophisticated reasoning capabilities with comprehensive vision-language understanding. Its unique thinking mode architecture enables unprecedented transparency in AI reasoning, while the MoE design ensures efficient resource utilization without compromising performance.
The model's versatility spans from scientific document analysis and code generation to GUI automation and educational content creation. With support for 32 languages and 256K native context length, it addresses diverse global applications while maintaining the computational efficiency necessary for practical deployment. As of 2026, it remains a strong open-weights pick alongside the newer Qwen 3.5-VL family and DeepSeek V4 line.