
Last updated: May 1, 2026.
What changed in this 2026 refresh: Pricing, framework versions, and competitive positioning verified current as of May 2026; Qwen3-VL-8B still leads the open-weight 8B-class on OCR and cost-adjusted quality.
Alibaba's Qwen team released Qwen3-VL on October 15, 2025 (8B/4B dense variants), with the full Qwen3-VL Technical Report following on November 27, 2025. Eighteen months later, the 8B Instruct and 8B Thinking checkpoints remain the strongest open-weight vision-language models in the 8–12B class — there is still no Qwen4-VL as of May 2026, and the Qwen3-VL family has expanded rather than been replaced.
This guide compares Qwen3-VL-8B-Instruct and Qwen3-VL-8B-Thinking with current 2026 pricing, current competitive context (Claude 4.7, GPT-5.5, Gemini 3, DeepSeek V4), and current deployment defaults.
Want the full picture? Read our continuously-updated GPT-5.5 Complete Guide (2026) — benchmarks, pricing, agent capabilities, and migration notes.
Want the full picture? Read our continuously-updated Qwen 3.5 Complete Guide (2026) — flavors, licensing, benchmarks, and on-device usage.
TL;DR
- Same 9B-parameter backbone, same 36T-token / 119-language pretraining, same Apache 2.0 license. The two checkpoints differ only in post-training.
- Instruct: ~45–60 tok/s on a single 4090, $0.08 / $0.50 per 1M tokens on OpenRouter, max 16,384 VL output tokens. Use it for high-volume production, OCR pipelines, chatbots.
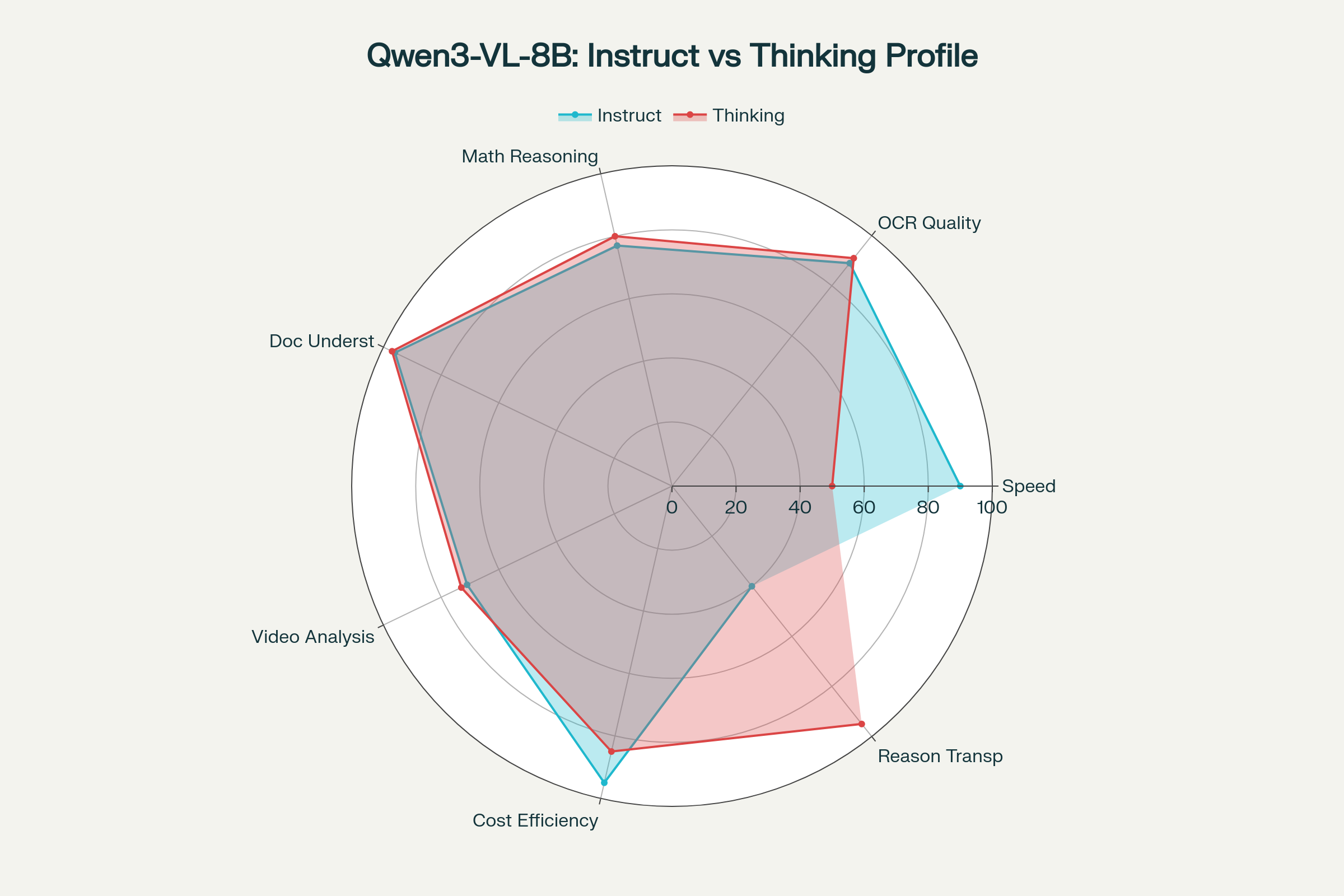
- Thinking: 1.5–2x slower, max 40,960 VL output tokens, generates explicit chain-of-thought. Beats Instruct by 2–4 points on MMMU, MathVista, OCRBench, and ChartX. Use it for STEM tutoring, medical/legal review, mockup-to-code.
- Cost vs. proprietary frontier: roughly 30–80x cheaper per query than GPT-5.5 or Claude 4.7 Sonnet for comparable vision-language quality at the 8B class.
What changed since the original October 2025 launch
- Pricing reset. OpenRouter and most aggregators list Qwen3-VL-8B-Instruct at $0.08 input / $0.50 output per 1M tokens (up from launch-window pricing of $0.035 / $0.138). Self-hosted economics improved as RTX 50-series and used 4090s pulled GPU prices down.
- Competitive landscape moved. Claude 3.5 Sonnet has been superseded by Claude 4.7 Sonnet; GPT-4o by GPT-5.5; Gemini 2.5 by Gemini 3; DeepSeek V3 by DeepSeek V4. Qwen3-VL-8B's relative cost advantage widened against the closed frontier.
- Tooling matured. vLLM 0.7+ and SGLang both ship first-class Qwen3-VL kernels with FA3. Ollama, LMStudio, and llama.cpp all support 8B Instruct/Thinking out of the box including FP8 and GGUF Q4 builds.
- Qwen3.5 / Qwen3.6 text models shipped, but no Qwen3.5-VL or Qwen4-VL. The vision-language line is still anchored on Qwen3-VL — the 8B variants are not legacy.
- Context still 256K native, expandable to 1M. No change.
For a wider view of how Qwen3-VL fits alongside the frontier reasoning models in 2026, see our pillar comparison DeepSeek V4 vs Claude vs GPT-5: AI coding model comparison (2026).
Architecture: what the two checkpoints share
Both 8B variants are dense transformers with ~9B total parameters (some sources round to 8.77B; Hugging Face card lists 9B). All parameters are active during inference — no expert routing — which keeps latency predictable.
Core innovations (identical across Instruct and Thinking)
- DeepStack vision encoder: multi-level ViT fusion that captures fine-grained visual detail. Drives the OCRBench and DocVQA performance.
- Interleaved-MRoPE: rotary positional embeddings allocated across time, width, height. Critical for long-video reasoning at 256K context.
- Text-timestamp alignment: precise event localization in video — the model can answer "at what timestamp does X occur" rather than just "does X occur".
- 32-language OCR (up from 19 in Qwen2.5-VL), robust to low-light, blur, and tilt.
- 3D spatial grounding — uncommon in the 8B class, useful for robotics and AR/VR pipelines.
Training foundation
Both checkpoints share the same pretraining: 36 trillion tokens across 119 languages, in three stages — General (S1, 30T+ tokens at 4K seq), Long Context (S2, extended to 32K), Extended Context (S3, full 256K). Differences emerge entirely from post-training.
Qwen3-VL-8B-Instruct: production default
Design
Standard supervised fine-tuning. Generates direct answers without explicit reasoning blocks. Optimized for low latency and predictable token consumption.
Recommended generation hyperparameters (May 2026, from official model card)
- Vision-language tasks: top_p=0.8, temperature=0.7, presence_penalty=1.5, max_new_tokens=16,384
- Text-only tasks: top_p=1.0, top_k=40, presence_penalty=2.0, max_new_tokens=32,768
Benchmarks
- MMMU: ~69–70
- MathVista: ~77
- OCRBench: 896
- DocVQA: ~96%
- RealWorldQA: ~71%
- ScreenSpot (GUI agent): ~94%
When Instruct is the right call
- Real-time chatbots and customer-service automation (sub-2-second response budget).
- High-volume document scanning, product cataloging, content moderation — 1.5–2x more requests per GPU than Thinking.
- Standard accuracy targets (90–95%) where reasoning transparency does not matter.
- API cost-sensitive deployments — shorter outputs cap spend.
Qwen3-VL-8B-Thinking: when you need the work shown
Design
Thinking is post-trained through a four-stage pipeline:
- CoT cold start: long chain-of-thought SFT across math, logic, coding, science.
- Reasoning RL: rule-based rewards for coherent intermediate steps, anti-hallucination.
- Thinking-mode fusion: blend reasoning data with general instruction following.
- General RL refinement: 20+ task categories (format, tool use, agent flows).
The model dynamically allocates reasoning budget — simple questions get short answers, hard ones spawn long <think> blocks.
Recommended hyperparameters (May 2026, official model card)
- Vision-language: top_p=0.95, top_k=20, temperature=1.0, presence_penalty=0.0, max_new_tokens=40,960
- Text-only: top_p=0.95, top_k=20, temperature=1.0, presence_penalty=1.5, max_new_tokens=32,768 (or 81,920 for AIME / LCB / GPQA-class problems)
Benchmarks
- MMMU: ~70–72 (+2–3 over Instruct)
- MathVista: ~79–80 (+2–3)
- OCRBench: 900–910 (+4–14)
- VideoMME: ~72–73 (+1–2)
- ChartX: ~84–85 (+1–2)
Headline gap looks small; on multi-step reasoning tasks the practical quality lift is closer to 10–18%.
When Thinking is the right call
- STEM tutoring — students learn from the reasoning, not just the answer.
- Medical imaging triage where audit trails are required.
- Legal/compliance document review.
- Mockup-to-code: 15–20% better than Instruct on visual-to-HTML/CSS conversion.
- 3D grounding, robotics, AR/VR — 15–20% accuracy lift on spatial tasks.
Side-by-side specifications
Architecture
| Specification | Qwen3-VL-8B-Instruct | Qwen3-VL-8B-Thinking |
|---|---|---|
| Total parameters | ~9B (8.77B) | ~9B (8.77B) |
| Architecture | Dense transformer | Dense transformer |
| Vision encoder | ViT + DeepStack | ViT + DeepStack |
| Positional encoding | Interleaved-MRoPE | Interleaved-MRoPE |
| Native context | 256K tokens | 256K tokens |
| Expandable context | 1M tokens | 1M tokens |
| Pretraining tokens | 36T | 36T |
| Languages | 119 | 119 |
| License | Apache 2.0 | Apache 2.0 |
Hyperparameter contrast (vision-language)
| Parameter | Instruct | Thinking | Effect |
|---|---|---|---|
| top_p | 0.8 | 0.95 | Thinking samples a wider tail |
| temperature | 0.7 | 1.0 | Thinking is more exploratory |
| presence_penalty | 1.5 | 0.0 | Instruct stays on-topic; Thinking can introduce intermediate concepts |
| max_new_tokens (VL) | 16,384 | 40,960 | Thinking fits a 2.5x longer reasoning chain |
Benchmark scoreboard
| Benchmark | Task | Instruct | Thinking | Winner |
|---|---|---|---|---|
| MMMU | Multimodal reasoning | ~69–70 | ~70–72 | Thinking |
| MathVista | Math reasoning | ~77 | ~79–80 | Thinking |
| OCRBench | Text recognition | 896 | 900–910 | Thinking |
| DocVQA | Document QA | ~96 | ~97 | Tie |
| RealWorldQA | Visual QA | ~71 | ~72 | Tie |
| VideoMME | Video understanding | ~71 | ~72–73 | Thinking |
| ScreenSpot | GUI agent | ~94 | ~94 | Tie |
| ChartX | Chart analysis | ~83 | ~84–85 | Thinking |
Deployment and hardware
VRAM by quantization
- BF16: 16–18 GB. Best quality, no degradation. RTX 4090 / RTX 5080 / A6000 / A100.
- FP8 (recommended for production): 8–9 GB, <1% benchmark loss. RTX 3090 / 4080 / 4070 Ti / 5070.
- GPTQ-Int8: 6–7 GB. Minor quality cost. RTX 3080 / 4070.
- 4-bit (AWQ / GGUF Q4_K_M): 4–5 GB. Noticeable quality loss but runs on RTX 3060 / 4060 / Mac M-series with 16 GB unified.
FP8 is the default deployment format for almost everyone — it halves VRAM at sub-1% benchmark cost.
Frameworks (2026 state)
- vLLM 0.7+: production default. 2–3x throughput vs. Transformers. First-class Qwen3-VL kernels with FA3.
- SGLang: strong alternative, particularly for structured output and multi-turn agents.
- Transformers: fine for prototyping; do not ship behind a load balancer.
- Ollama / LMStudio: one-command local deployment. Both ship Qwen3-VL 8B Instruct and Thinking out of the box.
- llama.cpp: GGUF Q4/Q5/Q8 builds for CPU and Mac Metal inference.
from vllm import LLM, SamplingParams
llm = LLM(
model="Qwen/Qwen3-VL-8B-Instruct-FP8",
trust_remote_code=True,
gpu_memory_utilization=0.75,
tensor_parallel_size=2,
seed=42,
)Latency and memory caveats for Thinking
- Inference latency: 1.5–2x slower wall-clock than Instruct because of longer outputs.
- KV-cache pressure: 40,960-token VL output budget inflates peak VRAM during batch processing — size your
max_num_seqsconservatively. - API token bill: 2–3x more output tokens per query for hard problems.
Pricing (May 2026)
Hosted API
OpenRouter (current published pricing):
- Input: $0.08 / 1M tokens
- Output: $0.50 / 1M tokens
- Context window served: 131,072 tokens; max output 32,768.
For a 1,000-input + 500-output query: ~$0.000330 — about $3.30 per 10,000 queries on Instruct.
Thinking penalty: if reasoning lifts output to 1,500 tokens (3x), per-query cost becomes ~$0.000830 — roughly 2.5x Instruct.
Alibaba Cloud Model Studio: enterprise rates by quote, generally competitive with OpenRouter.
Hugging Face Inference Endpoints: dedicated GPU pricing, billed by GPU-hour (currently ~$1.20/hr for an L4, ~$3.60/hr for an A100-80GB).
Self-hosted
| Option | Hardware cost | Run cost | Break-even vs AWS g5.xlarge |
|---|---|---|---|
| RTX 5080 (FP8) | ~$1,099 | ~$0.45/day electricity | ~46 days |
| RTX 4090 (FP8) | ~$1,499 (used) | ~$0.50/day | ~63 days |
| RTX 3090 (FP8) | ~$700 (used) | ~$0.40/day | ~30 days |
| AWS g5.xlarge (A10G) | — | $1.006/hr ≈ $720/mo | — |
Cost-optimization tactics
- Tiered routing: Instruct for the 80–90% of routine traffic; escalate to Thinking only when a complexity classifier or user tier demands it.
- FP8 by default: halves VRAM, <1% quality cost.
- Prompt caching: vLLM and SGLang both cache common prefixes — reuse system prompts and tool schemas.
- Batched OCR pipelines: pack pages into a single 256K-context request rather than one image per call.
Benchmark visualizations
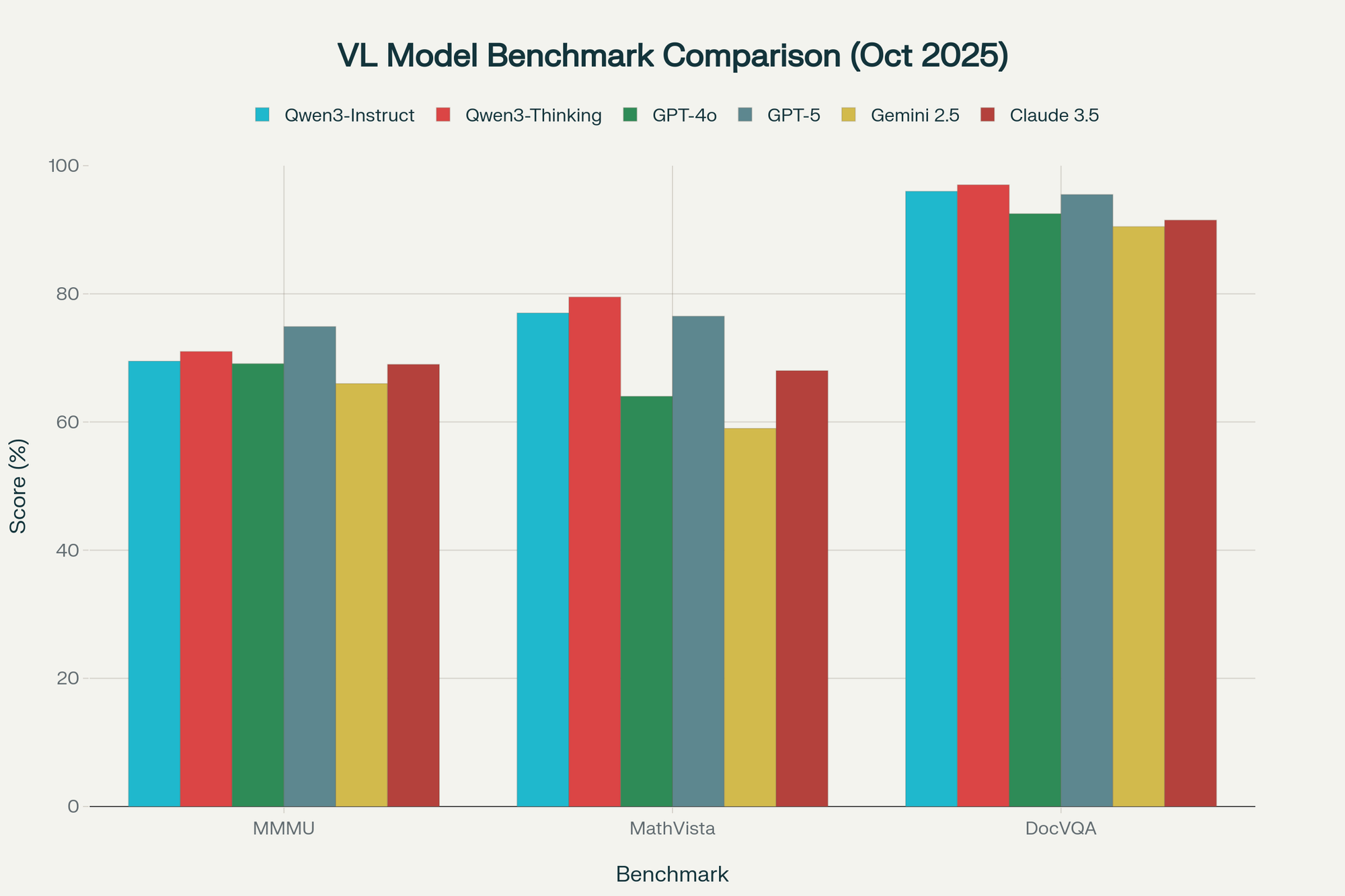
Performance comparison of Qwen3-VL-8B models against leading competitors across MMMU reasoning, MathVista, and DocVQA:
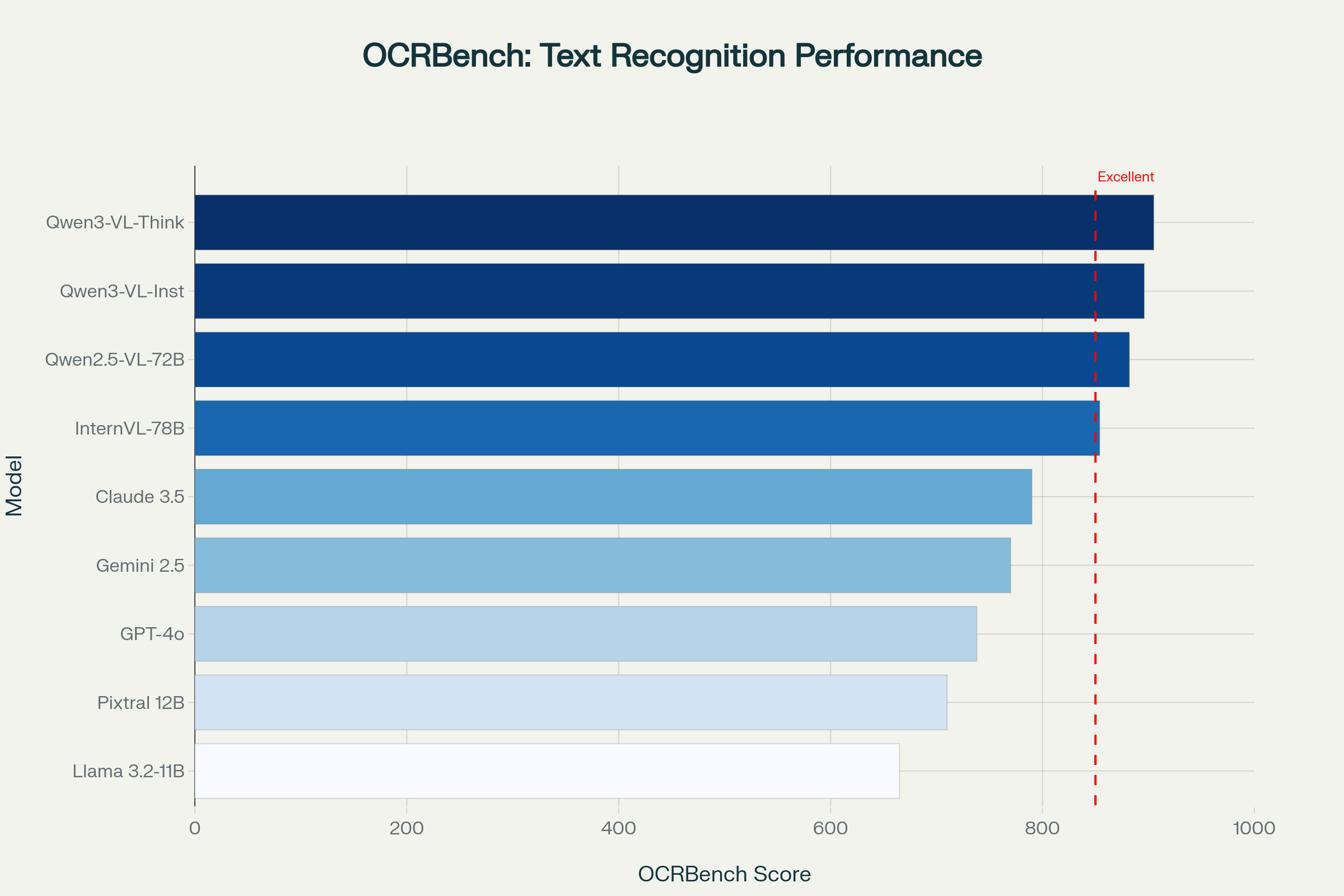
OCRBench scores showing Qwen3-VL-8B's text-recognition lead over much larger models:
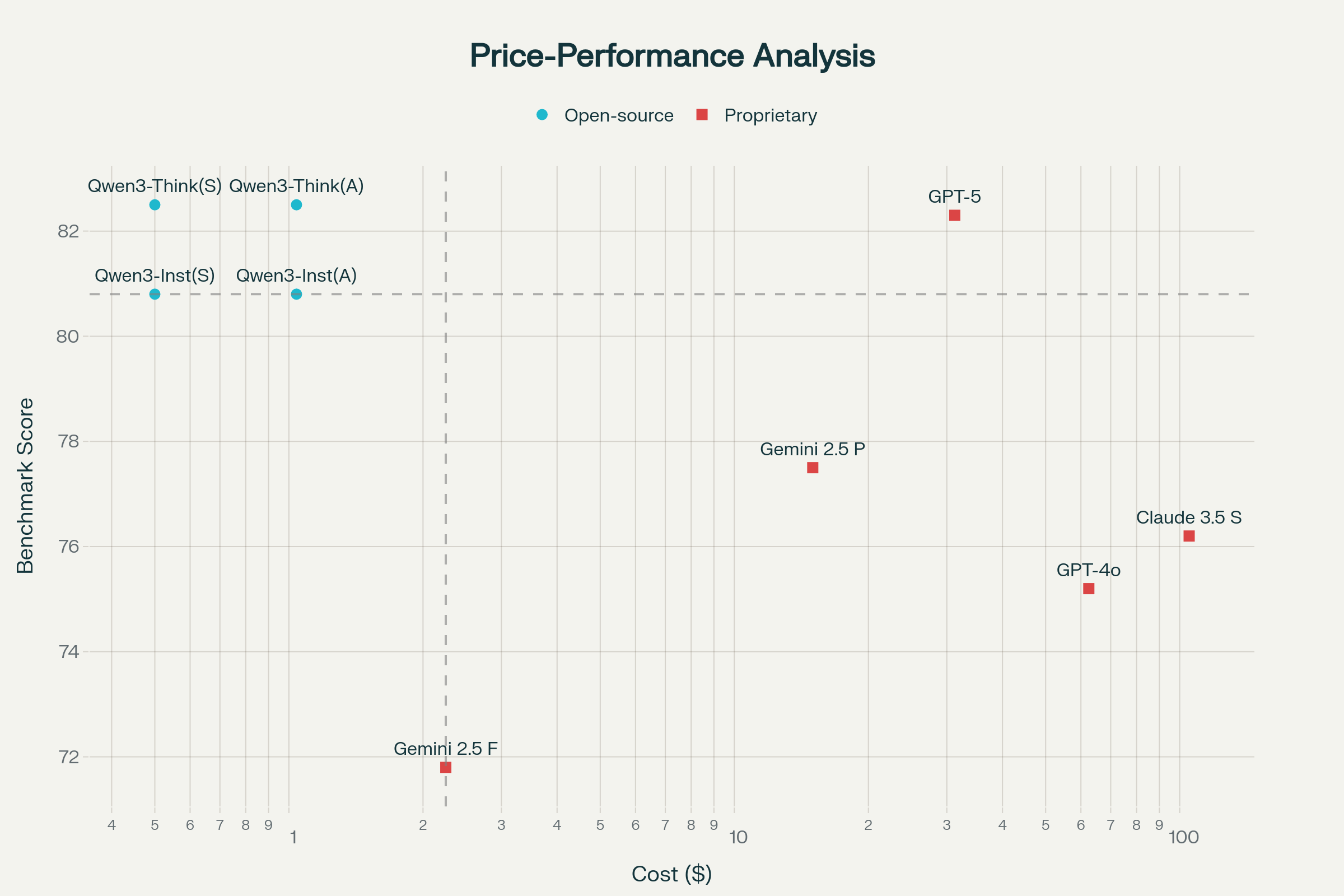
Price-performance analysis — Qwen3-VL-8B sits in the bottom-right "best value" quadrant:
Multi-dimensional capability radar — Instruct leads on speed and cost, Thinking on reasoning transparency and accuracy:
Competitive positioning (May 2026)
vs. the closed frontier (GPT-5.5, Claude 4.7 Sonnet, Gemini 3)
- Cost: Qwen3-VL-8B is roughly 30–80x cheaper per query than GPT-5.5 or Claude 4.7 Sonnet for vision-language tasks at comparable quality in the 8B-class accuracy band.
- OCR: Qwen3-VL-8B-Thinking still leads OCRBench in the open-weight category. Closed models hold a small edge on extremely noisy document conditions.
- Multilingual: 119 languages — broader than most closed alternatives.
- Where closed wins: ultra-long-context reasoning (Gemini 3 Pro at 2M effective context), bleeding-edge agentic coding (GPT-5.5, Claude 4.7), and tool-use ecosystems.
vs. similar-class open models
- Llama 3.3 Vision 11B: Qwen3-VL-8B-Thinking beats it on MMMU by ~40% relative, on MathVista by ~60%, on DocVQA by ~12 absolute points.
- Pixtral 12B: Qwen3-VL-8B-Thinking leads by 25–40% relative on reasoning benchmarks.
- InternVL 3: closer fight on reasoning; Qwen3-VL-8B still leads on OCR and agent tasks (ScreenSpot, OSWorld).
- DeepSeek-VL2: comparable on perception, Qwen3-VL ahead on agentic and OCR-heavy workloads.
Best-fit by segment
| Segment | Best choice (May 2026) | Why |
|---|---|---|
| Budget development | Qwen3-VL-8B-Instruct | Best perf-per-dollar; runs on a single consumer GPU |
| High-volume production | Qwen3-VL-8B-Instruct | 2x throughput of Thinking, 30–80x cheaper than closed |
| Educational technology | Qwen3-VL-8B-Thinking | Transparent reasoning + strong math |
| OCR-heavy workflows | Qwen3-VL-8B-Thinking | 900–910 OCRBench, 32-language |
| Enterprise compliance | Claude 4.7 Sonnet | Strongest safety filtering, enterprise contracts |
| Bleeding-edge reasoning | GPT-5.5 / DeepSeek V4 | Highest MMMU and SWE-bench in 2026 |
| Long-context multimodal | Gemini 3 Pro | 2M effective context, native video |
| Open-source research | Qwen3-VL-8B (either) | Apache 2.0, fine-tunable, no API lock-in |
Integration patterns
Hugging Face Transformers (prototype)
from transformers import AutoModelForVision2Seq, AutoProcessor
import torch
model_id = "Qwen/Qwen3-VL-8B-Instruct"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForVision2Seq.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
messages = [{
"role": "user",
"content": [
{"type": "image", "image": "invoice.png"},
{"type": "text", "text": "Extract line items as JSON."},
],
}]
inputs = processor.apply_chat_template(messages, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=2048, top_p=0.8, temperature=0.7)
print(processor.decode(out[0], skip_special_tokens=True))Ollama (local, one command)
ollama pull qwen3-vl:8b
ollama pull qwen3-vl:8b-thinking
ollama run qwen3-vl:8b "describe this image" < receipt.pngOpenRouter (hosted, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.environ["OPENROUTER_API_KEY"],
)
resp = client.chat.completions.create(
model="qwen/qwen3-vl-8b-instruct",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Title, category, 3 features."},
{"type": "image_url", "image_url": {"url": product_image_url}},
],
}],
)Parsing Thinking output
Thinking emits a <think>...</think> block before the final answer. In production, strip or store it separately:
import re
def split_thinking(text):
m = re.search(r"<think>(.*?)</think>(.*)", text, re.DOTALL)
if not m:
return "", text
return m.group(1).strip(), m.group(2).strip()
reasoning, answer = split_thinking(model_output)Fine-tuning on domain data
Both checkpoints support LoRA and QLoRA fine-tuning via Unsloth, Axolotl, and LLaMA-Factory. Realistic budgets in May 2026:
- QLoRA on a single RTX 4090 — 4-bit base + LoRA adapters, batch size 1, gradient accumulation 16, ~24 hours for 50K-sample SFT.
- LoRA on 2x A100-80GB — BF16, batch size 4, ~6 hours for the same dataset.
- Full fine-tune — needs 4–8x A100/H100; rarely worthwhile at 8B scale, LoRA is usually within 1 point.
Two patterns work well:
- Instruct base + domain LoRA for production OCR/captioning at lower latency.
- Thinking base + domain LoRA when you need reasoning chains in a specific vocabulary (medical terms, legal citations).
Worked examples
1. Medical imaging triage (Thinking)
Chest X-ray review demands explicit reasoning so radiologists can audit. The Thinking model emits a <think> block stepping through lung fields, cardiac silhouette, mediastinum, then a differential. The 12–18% reliability lift over Instruct justifies the latency and cost.
2. E-commerce catalog generation (Instruct)
10,000 product images per day → title + category + 3 features. Instruct delivers ~94% accuracy at 2x Thinking's throughput. Cost difference compounds at volume: ~$80 vs ~$190 per 10K products on hosted API.
3. STEM tutoring (Thinking)
For d/dx[sin(3x²)], Thinking shows the chain-rule decomposition step by step before stating 6x·cos(3x²). The reasoning is the deliverable; the answer is incidental.
Speed vs. quality trade-offs
| Test category | Sample task | Metric | Instruct | Thinking |
|---|---|---|---|---|
| Speed | Image captioning, simple Q&A | Tokens/sec | 45–60 | 30–40 |
| Accuracy | Math, logic puzzles | Correct % | 77–83 | 79–85 |
| OCR | Documents, receipts | Char error rate | 0.8–1.2% | 0.6–1.0% |
| Multi-step reasoning | Multi-step problems | Solution completeness | 65–70% | 80–88% |
| Video | Event detection | Temporal accuracy | 71% | 72–73% |
| Code from mockup | Image → HTML/CSS | Functional accuracy | 78–82% | 85–92% |
| Spatial | 3D positioning | Position error (cm) | 4.2–5.1 | 2.8–3.6 |
Quantified scenarios
1,000 medical images. Instruct: 2 hours, 92% accuracy, 80 false negatives, ~$50 API cost. Thinking: 4 hours, 96% accuracy, 40 false negatives, ~$120. The 50% reduction in missed findings is worth the 2.4x cost in healthcare contexts.
10,000 product images. Instruct: 8 hours, 94%, 600 manual fixes, ~$80. Thinking: 16 hours, 96%, 400 fixes, ~$190. For most e-commerce flows, Instruct's speed and cost win.
Agent and GUI control
Qwen3-VL was explicitly designed as an agentic backbone. The 8B variants drive ScreenSpot, OSWorld, and AndroidWorld benchmarks at a level where you can build practical computer-use agents on consumer hardware:
- ScreenSpot ~94% — element grounding for click/scroll actions.
- OSWorld — multi-step desktop task completion at parity with closed 70B-class agents.
- AndroidWorld — mobile UI navigation; competitive with proprietary mobile-agent stacks.
Typical agentic stack in May 2026:
- Perception: Qwen3-VL-8B-Thinking for screen parsing and plan formation.
- Action: Qwen3-VL-8B-Instruct (or Qwen3.6-Coder for shell/code) for fast, deterministic action emission.
- Tool layer: pyautogui / Playwright / Appium executor; observation back to the perception model on each turn.
Security and deployment hygiene
- Sandbox image inputs. Untrusted user images can carry adversarial perturbations. Resize/recompress through a separate process before passing to the model.
- Strip Thinking blocks before display if the chain-of-thought might leak system prompt content or sensitive intermediate reasoning.
- Rate-limit by output tokens, not just requests — Thinking can blow your budget on a single hard prompt.
- Pin model revision in production — Hugging Face revisions have shifted twice since launch to fix tokenizer issues. Use
revision="..."notmain. - Trust-remote-code is required; audit the repo before pulling on a new release.
Troubleshooting common issues
- OOM at 16K+ context with FP8: lower
gpu_memory_utilizationto 0.7, dropmax_num_seqs, or move to FP8 KV cache (vLLM--kv-cache-dtype fp8). - Garbled OCR on rotated documents: the model handles tilt up to ~25°, but cleaner output comes from running OpenCV deskew first.
- Thinking refuses to emit reasoning: temperature too low; raise to 1.0 and presence_penalty to 0.0 per the official card.
- Tokenizer mismatch on Ollama:
ollama pull --insecureis not the fix. Update Ollama to ≥0.8 and re-pull the tag. - Slow first request on vLLM: vision encoder warm-up. Send a dummy image at startup.
Limitations
Shared
- Hallucination: Thinking makes hallucinations more visible by emitting reasoning, but does not eliminate them.
- Compute floor: BF16 needs 16 GB VRAM minimum; FP8 brings this to 8–9 GB.
- Knowledge cutoff: pretraining data ends mid-2025. For events after that, ground responses with retrieval.
Instruct-specific
- Opaque decision-making — hard to debug.
- 16,384 VL output cap can truncate long structured outputs.
- 10–15% behind Thinking on multi-step problems.
Thinking-specific
- 1.5–2x slower; not suited to real-time UX.
- Verbose by default — over-reasons trivial prompts.
- Output costs scale 2.5x faster on hosted APIs.
Decision framework
Use Instruct when
- Latency target under 2 seconds.
- Throughput target above 1,000 requests/hour.
- Standard 90–95% accuracy is enough.
- Reasoning transparency is not required.
- Cost optimization is a primary constraint.
Use Thinking when
- Tasks need multi-step reasoning that has to be visible.
- Audit trails matter (medical, legal, education).
- The 5–18% accuracy lift justifies 2x cost and latency.
- You need structured spatial / 3D / coding-from-mockup output.
Hybrid is the usual answer
Most production deployments tier the two. A complexity classifier (or just the user's subscription tier) routes 80–90% of traffic to Instruct; the rest escalates to Thinking. Below is a sketch of that router:
def route(query, complexity_score, user):
if complexity_score > 0.7:
return qwen3_vl_8b_thinking
if user.tier == "premium":
return qwen3_vl_8b_thinking
return qwen3_vl_8b_instructFuture outlook
- Successor likely in late 2026 / early 2027. Qwen team has shipped Qwen3.5 and Qwen3.6 on the text side; the next-gen vision-language line (likely Qwen3.5-VL or Qwen4-VL) is unannounced as of May 2026.
- Quantization will keep improving. 4-bit GGUF Q4_K_M already runs Qwen3-VL-8B at usable quality on RTX 3060-class GPUs and Mac M-series.
- Agentic stacks. Qwen3-VL's native GUI control (ScreenSpot / OSWorld leadership) is the foundation for an open-source equivalent of Anthropic's Computer Use and OpenAI's Operator.
- Fine-tuning ecosystem. Apache 2.0 means domain-specific Qwen3-VL fine-tunes (medical, legal, manufacturing) keep landing on Hugging Face — check there before training from scratch.
Extended benchmark context (May 2026)
Beyond the headline numbers, here is how Qwen3-VL-8B (Instruct / Thinking) compares to a fuller competitive set on the most-cited 2026 benchmarks. Numbers are rounded from public leaderboards and vendor cards as of May 2026; exact figures shift as evaluation harnesses update.
| Model | Params | MMMU | MathVista | OCRBench | DocVQA | VideoMME |
|---|---|---|---|---|---|---|
| Qwen3-VL-8B-Instruct | ~9B | ~70 | ~77 | 896 | ~96 | ~71 |
| Qwen3-VL-8B-Thinking | ~9B | ~71 | ~80 | 905 | ~97 | ~73 |
| Qwen3-VL-32B-Thinking | ~32B | ~76 | ~84 | 915 | ~97 | ~76 |
| Qwen3-VL-235B-A22B | 235B MoE | ~80 | ~87 | 920 | ~98 | ~79 |
| Llama 3.3 Vision 11B | 11B | ~51 | ~50 | 665 | ~86 | ~58 |
| Pixtral 12B | 12B | ~54 | ~57 | 720 | ~89 | ~60 |
| InternVL 3 8B | ~8B | ~68 | ~74 | 880 | ~95 | ~70 |
| DeepSeek-VL2 (small) | 16B MoE | ~67 | ~71 | 860 | ~94 | ~68 |
| Gemini 3 Flash | closed | ~74 | ~76 | 880 | ~95 | ~75 |
| Gemini 3 Pro | closed | ~82 | ~88 | 910 | ~97 | ~82 |
| Claude 4.7 Sonnet | closed | ~78 | ~82 | 900 | ~96 | ~74 |
| GPT-5.5 | closed | ~82 | ~85 | 905 | ~97 | ~80 |
Two observations land hard here. First, Qwen3-VL-8B-Thinking holds its own on OCRBench and DocVQA against the closed frontier — text-recognition has saturated faster than reasoning. Second, the gap on MMMU and MathVista is real (8–12 points to GPT-5.5 / Gemini 3 Pro), and that gap is the price you pay for an open-weight, locally-runnable model.
Cost projections at scale (May 2026)
Concrete dollar figures for a 1M-query/month workload (1,000 input + 500 output tokens average), comparing self-hosted, OpenRouter Qwen3-VL-8B, and three closed alternatives:
| Path | Per-query cost | 1M/month cost | Notes |
|---|---|---|---|
| Self-hosted RTX 4090 FP8 | ~$0.00005 | ~$50 | Amortized GPU + electricity, single node |
| Self-hosted 2x A100 vLLM | ~$0.00012 | ~$120 | Higher throughput, redundancy |
| OpenRouter Qwen3-VL-8B-Instruct | ~$0.00033 | ~$330 | $0.08 in / $0.50 out per 1M |
| OpenRouter Qwen3-VL-8B-Thinking | ~$0.00083 | ~$830 | 3x output tokens average |
| Gemini 3 Flash | ~$0.00200 | ~$2,000 | Closed but cheap of its tier |
| Claude 4.7 Sonnet | ~$0.01000 | ~$10,000 | ~$3 / $15 per 1M tokens |
| GPT-5.5 | ~$0.01200 | ~$12,000 | ~$3.50 / $17.50 per 1M tokens |
For a startup or internal tool processing a few million queries monthly, the difference between self-hosted Qwen3-VL-8B and Claude 4.7 Sonnet is roughly two engineers' annual salaries. That gap is what keeps Qwen3-VL on production roadmaps even as the closed frontier outscores it on raw benchmarks.
Migration from Qwen2.5-VL-7B
If you are running Qwen2.5-VL-7B in production, the migration to Qwen3-VL-8B is straightforward but worth a deliberate pass:
- Tokenizer is compatible but vocabulary expanded for new languages. Re-test your prompt-token budgeting.
- System-prompt format uses the same
<|im_start|>/<|im_end|>roles. No template change needed. - Default hyperparameters changed — Qwen2.5 used temperature=0.7/top_p=0.9 for VL; Qwen3 differentiates Instruct (0.7/0.8) from Thinking (1.0/0.95). Update your inference config.
- Vision encoder upgraded — DeepStack improves OCR by 6–14 points. Re-tune downstream OCR post-processing thresholds.
- Context window jumped from 32K to 256K native. If you were chunking long documents, you can stop.
- Benchmarks lift: MMMU 58.6 → 70-72 (Thinking), MathVista 68.2 → 79-80, OCRBench 864 → 905. Most regressions during migration come from tighter Thinking output that breaks downstream regex parsers — fix those first.
Conclusion
The Instruct/Thinking split is not "better vs worse" — it is "fast and predictable" vs "deeper but pricier and slower". Both remain the best Apache-2.0 vision-language checkpoints in the 8B class as of May 2026, both still hold up against the closed frontier on cost-adjusted quality, and the same 9B backbone keeps your inference stack uniform if you deploy both behind a router.
Related on Codersera
- DeepSeek V4 vs Claude vs GPT-5: AI coding model comparison (2026) — pillar comparison covering the closed frontier alongside open-weight options.
- Running Qwen3 8B on Windows: a comprehensive guide
- Run Qwen3 8B on Mac: an installation guide
- Qwen3-VL-30B-A3B-Thinking: deployment guide